| Citation: | DI Jing, LIANG Chan, LIU Ji-zhao, LIAN Jing. Infrared and visible image fusion guided by cross-domain interactive attention and contrastive learning[J]. Chinese Optics, 2025, 18(2): 317-332. doi: 10.37188/CO.2024-0147

|
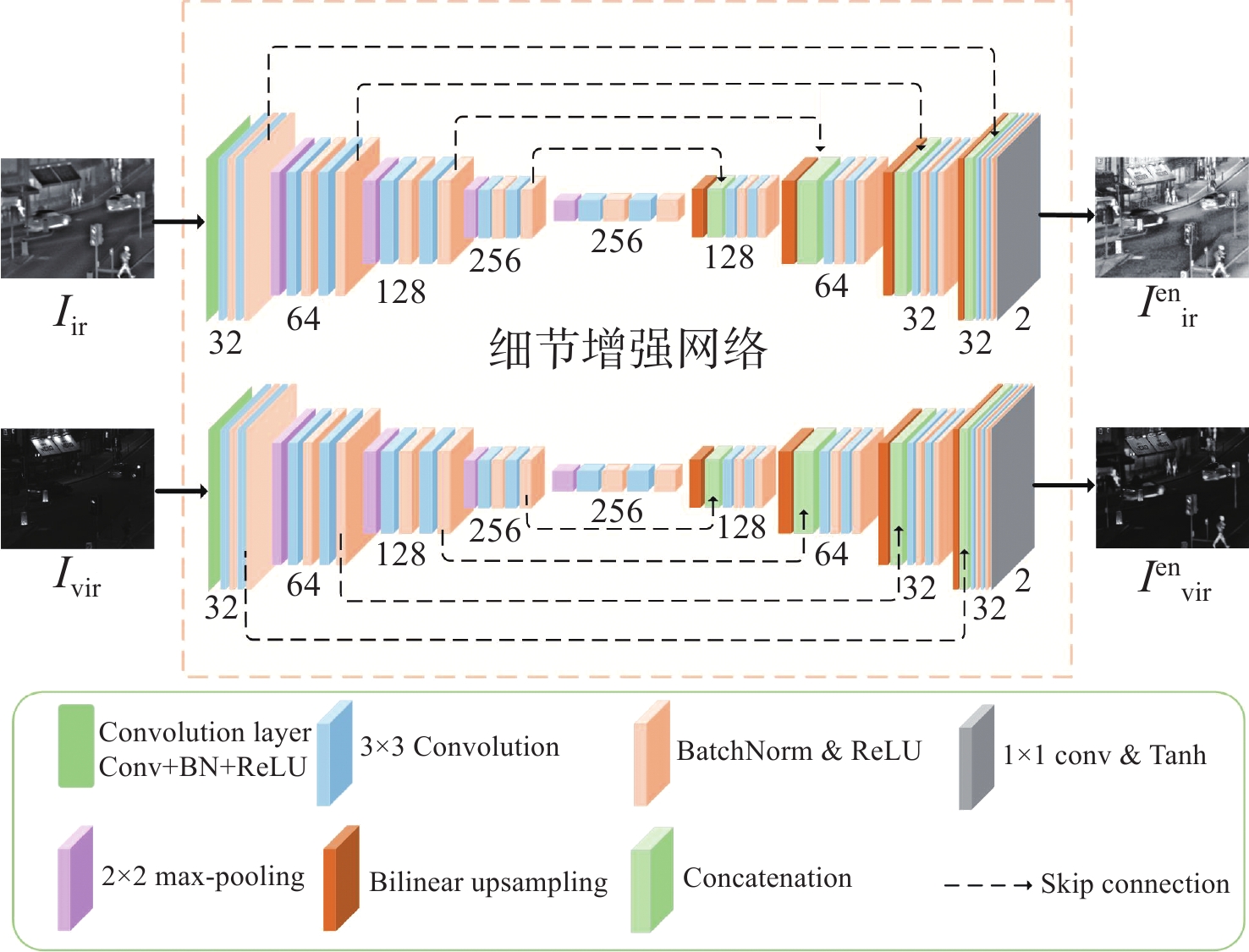
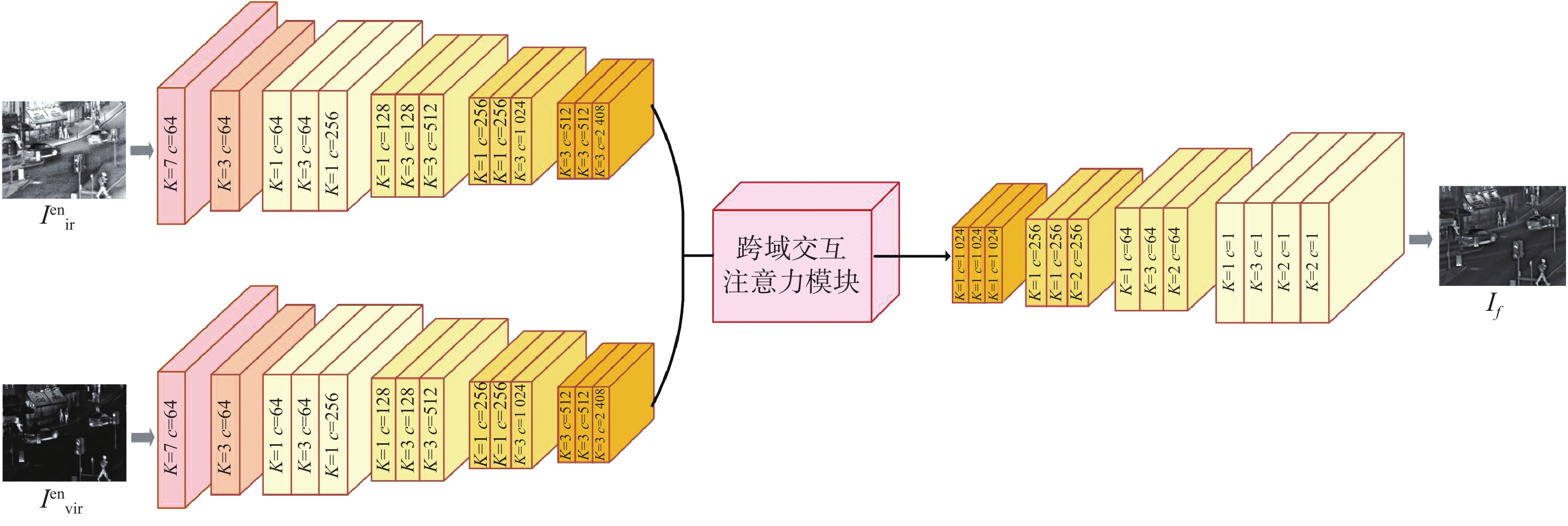
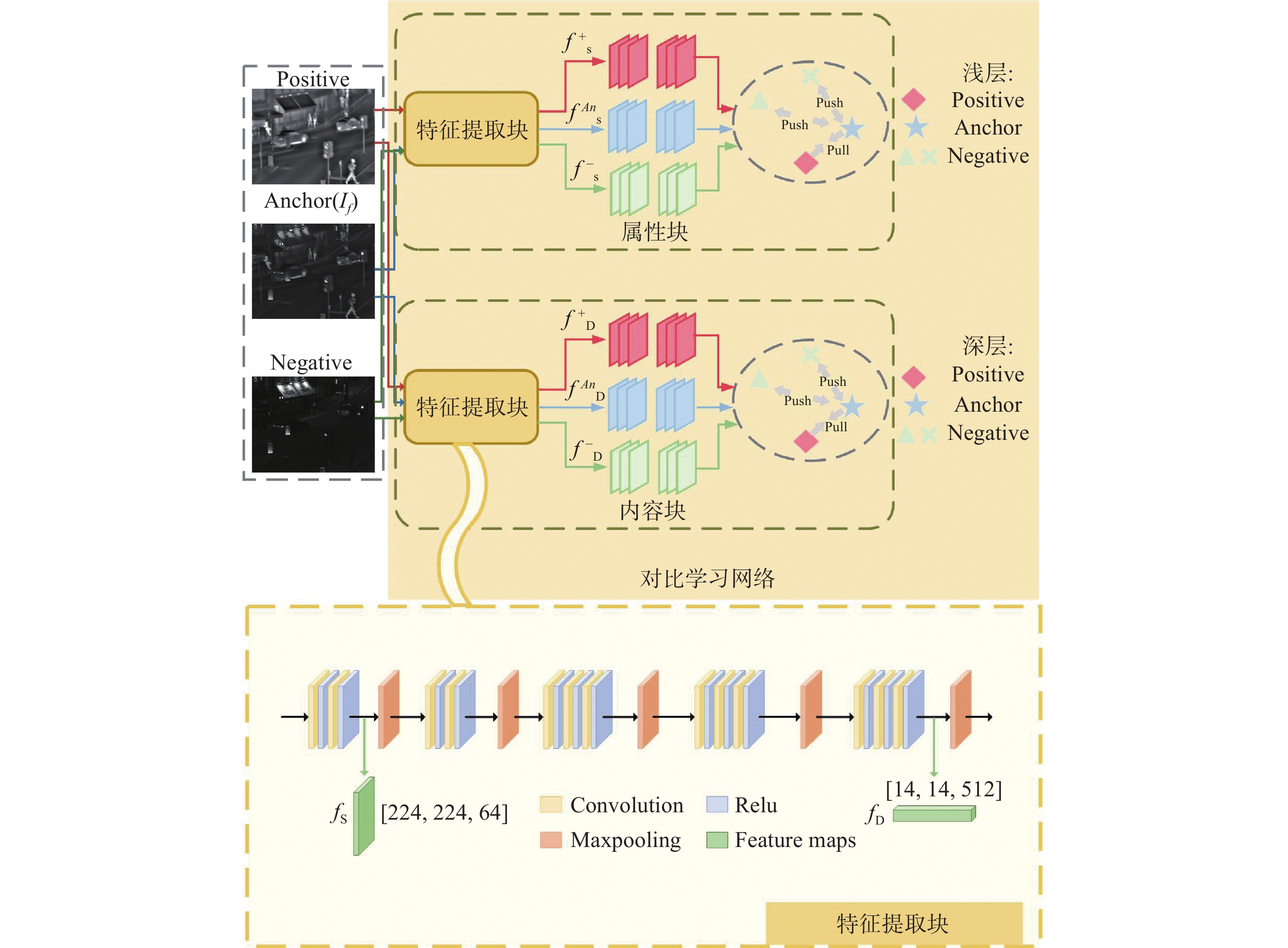
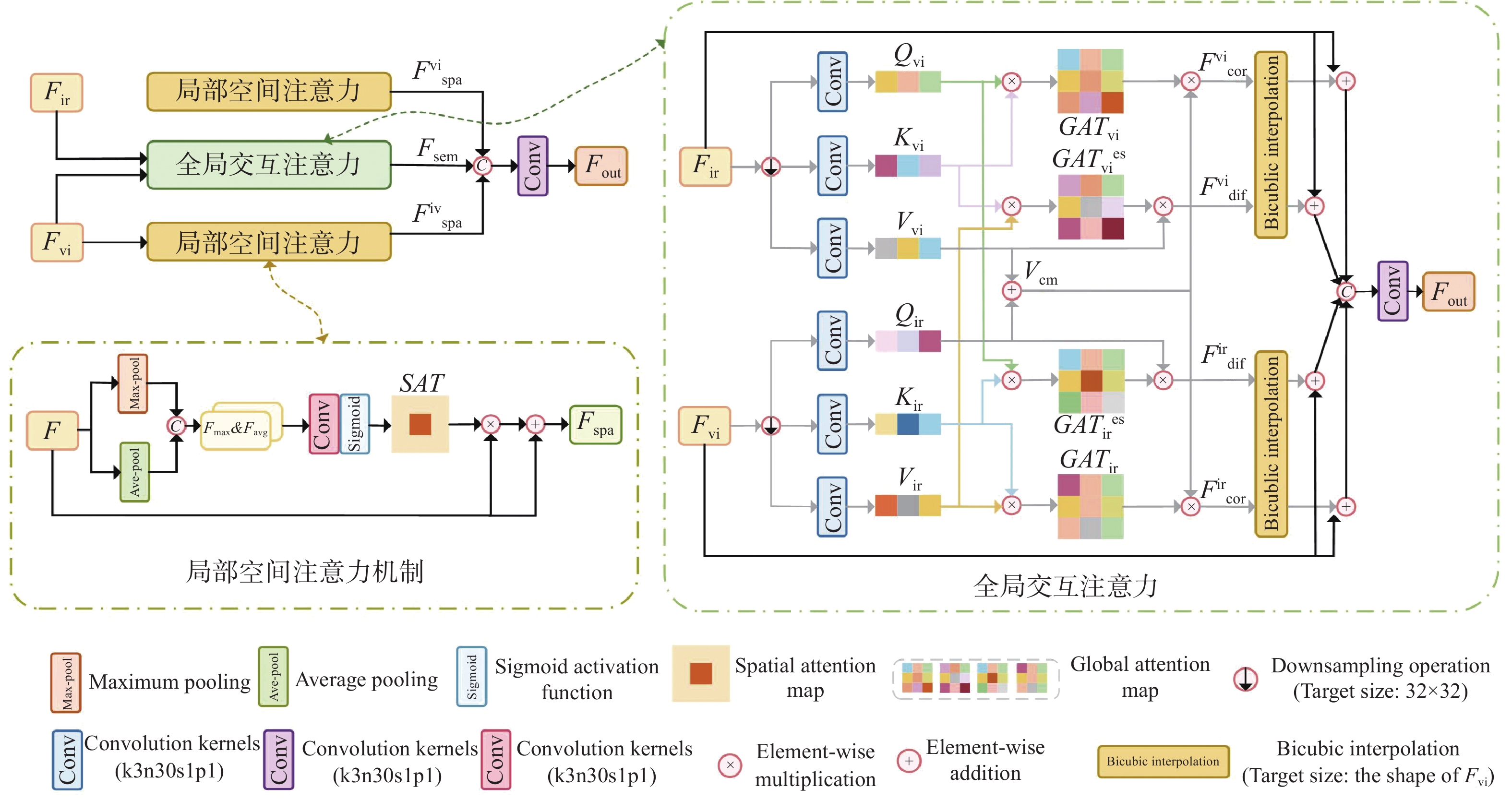
Aiming at the problems in existing infrared and visible image fusion methods, such as the difficulty in fully extracting and preserving the source image details, contrast, and blurred texture details, this paper proposes an infrared and visible image fusion method guided by cross-domain interactive attention and contrastive learning. First, a dual-branch skip connection detail enhancement network was designed to separately extract and enhance detail information from infrared and visible images, using skip connections to prevent information loss and generate enhanced detail images. Next, a fusion network combining a dual-branch encoder and cross-domain interactive attention module was constructed to ensure sufficient feature interaction during fusion, and the decoder was used to reconstruct the final fused image. Then, a contrastive learning network was introduced, performing shallow and deep attribute and content contrastive learning from the contrastive learning block, optimizing feature representation, and further improving the performance of the fusion network. Finally, to constrain network training and retain the inherent features of the source images, a contrast-based loss function was designed to assist in preserving source image information during fusion. The proposed method is qualitatively and quantitatively compared with current state-of-the-art fusion methods. Experimental results show that the eight objective evaluation metrics of the proposed method significantly outperform the comparison methods on the TNO, MSRS, and RoadSence datasets. The fused images produced by the proposed method have rich detail textures, enhanced sharpness, and contrast, effectively improving target recognition and environmental perception in real-world applications such as road traffic and security surveillance.

| [1] |
ARCHANA R, JEEVARAJ P S E. Deep learning models for digital image processing: a review[J]. Artificial Intelligence Review, 2024, 57(1): 11. doi: 10.1007/s10462-023-10631-z
|
| [2] |
LI H, WU X J. CrossFuse: a novel cross attention mechanism based infrared and visible image fusion approach[J]. Information Fusion, 2024, 103: 102147. doi: 10.1016/j.inffus.2023.102147
|
| [3] |
YANG B, HU Y X, LIU X W, et al. CEFusion: an infrared and visible image fusion network based on cross-modal multi-granularity information interaction and edge guidance[J]. IEEE Transactions on Intelligent Transportation Systems, 2024, 25(11): 17794-17809. doi: 10.1109/TITS.2024.3426539
|
| [4] |
NAHATA D, OTHMAN K, NAHATA D, et al. Exploring the challenges and opportunities of image processing and sensor fusion in autonomous vehicles: a comprehensive review[J]. AIMS Electronics and Electrical Engineering, 2023, 7(4): 271-321. doi: 10.3934/electreng.2023016
|
| [5] |
程博阳, 李婷, 王喻林. 基于视觉显著性加权与梯度奇异值最大的红外与可见光图像融合[J]. 中国光学(中英文),2022,15(4):675-688. doi: 10.37188/CO.2022-0124
CHENG B Y, LI T, WANG Y L. Fusion of infrared and visible light images based on visual saliency weighting and maximum gradient singular value[J]. Chinese Optics, 2022, 15(4): 675-688. (in Chinese). doi: 10.37188/CO.2022-0124
|
| [6] |
ZHANG Y M, LEE H J. Infrared and visible image fusion based on multi-scale decomposition and texture preservation model[C]. Proceedings of 2021 International Conference on Computer Engineering and Artificial Intelligence (ICCEAI), IEEE, 2021: 335-339.
|
| [7] |
GAO M L, ZHOU Y N, ZHAI W ZH, et al. SaReGAN: a salient regional generative adversarial network for visible and infrared image fusion[J]. Multimedia Tools and Applications, 2023, 83(22): 61659-61671. doi: 10.1007/s11042-023-14393-2
|
| [8] |
LI X L, LI Y F, CHEN H J, et al. RITFusion: reinforced interactive transformer network for infrared and visible image fusion[J]. IEEE Transactions on Instrumentation and Measurement, 2024, 73: 5000916.
|
| [9] |
CHEN J, LI X J, LUO L B, et al. Infrared and visible image fusion based on target-enhanced multiscale transform decomposition[J]. Information Sciences, 2020, 508: 64-78. doi: 10.1016/j.ins.2019.08.066
|
| [10] |
刘先红, 陈志斌, 秦梦泽. 结合引导滤波和卷积稀疏表示的红外与可见光图像融合[J]. 光学 精密工程,2018,26(5):1242-1253. doi: 10.3788/OPE.20182605.1242
LIU X H, CHEN ZH B, QIN M Z. Infrared and visible image fusion using guided filter and convolutional sparse representation[J]. Optics and Precision Engineering, 2018, 26(5): 1242-1253. (in Chinese). doi: 10.3788/OPE.20182605.1242
|
| [11] |
LI Y H, LIU G, BAVIRISETTI D P, et al. Infrared-visible image fusion method based on sparse and prior joint saliency detection and LatLRR-FPDE[J]. Digital Signal Processing, 2023, 134: 103910. doi: 10.1016/j.dsp.2023.103910
|
| [12] |
LIU Y, CHEN X, WARD R K, et al. Image fusion with convolutional sparse representation[J]. IEEE Signal Processing Letters, 2016, 23(12): 1882-1886. doi: 10.1109/LSP.2016.2618776
|
| [13] |
PRABHAKAR K R, SRIKAR V S, VENKATESH BABU R. DeepFuse: a deep unsupervised approach for exposure fusion with extreme exposure image pairs[C]. Proceedings of the 2017 IEEE International Conference on Computer Vision, IEEE, 2017: 4724-4732.
|
| [14] |
LI H, WU X J, DURRANI T. NestFuse: an infrared and visible image fusion architecture based on nest connection and spatial/channel attention models[J]. IEEE Transactions on Instrumentation and Measurement, 2020, 69(12): 9645-9656. doi: 10.1109/TIM.2020.3005230
|
| [15] |
LI H, WU X J, KITTLER J. RFN-Nest: an end-to-end residual fusion network for infrared and visible images[J]. Information Fusion, 2021, 73: 72-86. doi: 10.1016/j.inffus.2021.02.023
|
| [16] |
MA J Y, TANG L F, FAN F, et al. SwinFusion: cross-domain long-range learning for general image fusion via Swin transformer[J]. IEEE/CAA Journal of Automatica Sinica, 2022, 9(7): 1200-1217. doi: 10.1109/JAS.2022.105686
|
| [17] |
ZHAO Z X, BAI H W, ZHANG J SH, et al. CDDFuse: correlation-driven dual-branch feature decomposition for multi-modality image fusion[C]. Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, IEEE, 2023: 5906-5916.
|
| [18] |
WANG X, GUAN ZH, QIAN W H, et al. CS2Fusion: contrastive learning for self-supervised infrared and visible image fusion by estimating feature compensation map[J]. Information Fusion, 2024, 102: 102039. doi: 10.1016/j.inffus.2023.102039
|
| [19] |
HE K M, FAN H Q, WU Y X, et al. Momentum contrast for unsupervised visual representation learning[C]. Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, IEEE, 2020: 9726-9735.
|
| [20] |
XU H, MA J Y, JIANG J J, et al. U2Fusion: a unified unsupervised image fusion network[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(1): 502-518. doi: 10.1109/TPAMI.2020.3012548
|
| [21] |
TANG L F, YUAN J T, ZHANG H, et al. PIAFusion: a progressive infrared and visible image fusion network based on illumination aware[J]. Information Fusion, 2022, 83-84: 79-92. doi: 10.1016/j.inffus.2022.03.007
|
| [22] |
TANG L F, DENG Y X, MA Y, et al. SuperFusion: a versatile image registration and fusion network with semantic awareness[J]. IEEE/CAA Journal of Automatica Sinica, 2022, 9(12): 2121-2137. doi: 10.1109/JAS.2022.106082
|
| [23] |
TANG L F, YUAN J T, MA J Y. Image fusion in the loop of high-level vision tasks: a semantic-aware real-time infrared and visible image fusion network[J]. Information Fusion, 2022, 82: 28-42. doi: 10.1016/j.inffus.2021.12.004
|
| [24] |
LIU J Y, FAN X, HUANG ZH B, et al. Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection[C]. Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, IEEE, 2022: 5792-5801.
|
| [25] |
TANG L F, XIANG X Y, ZHANG H, et al. DIVFusion: darkness-free infrared and visible image fusion[J]. Information Fusion, 2023, 91: 477-493. doi: 10.1016/j.inffus.2022.10.034
|
| [26] |
ZHAO Z X, BAI H W, ZHU Y ZH, et al. DDFM: denoising diffusion model for multi-modality image fusion[C]. Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision, IEEE, 2023: 8048-8059.
|
| [27] |
LI H, XU T Y, WU X J, et al. LRRNet: a novel representation learning guided fusion network for infrared and visible images[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(9): 11040-11052. doi: 10.1109/TPAMI.2023.3268209
|
| [28] |
CHEN H R, DENG L, CHEN ZH X, et al. SFCFusion: spatial-frequency collaborative infrared and visible image fusion[J]. IEEE Transactions on Instrumentation and Measurement, 2024, 73: 5011615.
|
| [29] |
LIU J Y, LIN R J, WU G Y, et al. CoCoNet: coupled contrastive learning network with multi-level feature ensemble for multi-modality image fusion[J]. International Journal of Computer Vision, 2024, 132(5): 1748-1775. doi: 10.1007/s11263-023-01952-1
|

Figures(10) / Tables(4)




 DownLoad:
DownLoad: