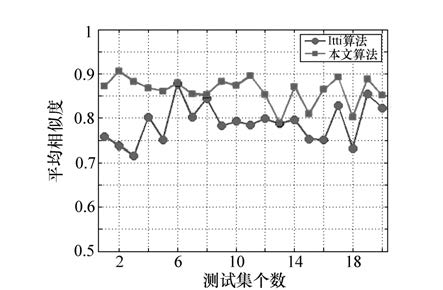
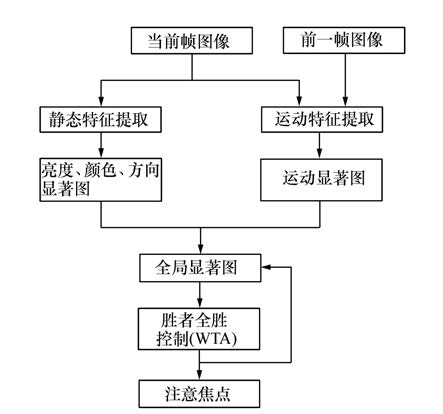
For the lack of top-down task guidance and dynamic information processing of traditional visual saliency model, a visual saliency model fused with the motion features is designed and implemented. The static features and motion features are extracted based on the proposed model. The static features are extracted from the intensity, color and orientation channel of the current frame image. The motion features are extracted based on the multi-scales difference method. The saliency maps of four channels can be obtained by filtering and difference. Based on the proposed model a method of parameter estimation for multi channel is proposed to calculate the similarity between the region of interesting of current image and the region of interesting of eyes movement, then guide to generate the global saliency map, which can provide a calculation mechanism for accurate location on images. 20 groups of video image sequences(50 images per group) are selected for the experiment. Experimental results show that the average similarity of focus of attention is 0.87. The proposed method can more efficiently and accurately locate the region where the searched target may be present and can improve the efficiency of target searching.






 DownLoad:
DownLoad: