


-
摘要:
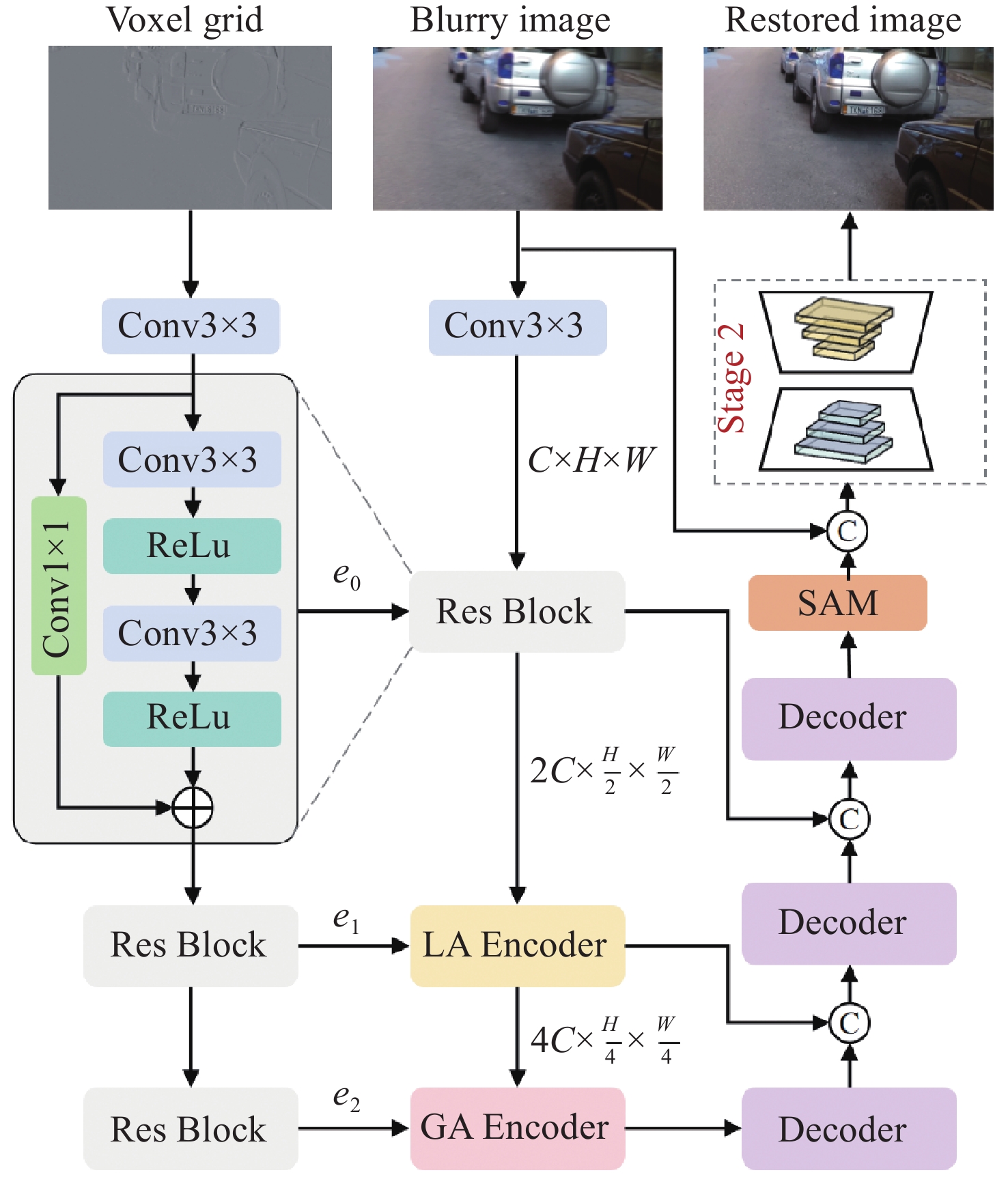
针对单帧图像去模糊固有的不适定性,以及现有扩散模型推理延迟高、状态空间模型跨模态交互不足的问题,本文提出一种端到端的事件融合多头注意力网络EFMAN,利用事件相机的高频时空先验实现高质量复原。首先,构建跨模态自适应注意力机制,将异步高频事件流与同步RGB特征进行时空维度精确配准,弥补曝光空缺。接着,针对传感器固有噪声干扰,设计特征增强注意力模块FEA,通过全局上下文建模强化特征抗噪鲁棒性。然后,引入轻量级通道-空间注意力模块LCSA,在降低计算冗余的同时完成特征响应自适应权重校准。最后,构建涵盖像素、特征及梯度域的多维联合损失,协同优化多尺度约束以保证微观纹理与全局结构一致。实验表明,该方法在保持高效推理的同时显著提升性能。相比基线,在GoPro数据集上PSNR和SSIM提升1.19 dB和0.005;在REBlur上提升0.38 dB和0.003,已达先进水平。EFMAN有效解决了多模态对齐与噪声干扰问题,在质量与效率间取得平衡,适用于高动态及剧烈运动场景下的清晰图像重建。
Abstract:Single-frame image deblurring remains an inherently ill-posed problem. Furthermore, existing diffusion models suffer from high inference latency, while state space models lack sufficient cross-modal interaction capabilities. To overcome these limitations, we propose an end-to-end Event-fusion Multi-head Attention Network (EFMAN) that exploits high-frequency spatiotemporal priors from event cameras for high-quality image restoration. Specifically, a cross-modal adaptive attention mechanism is designed to precisely align asynchronous high-frequency event streams with synchronous RGB features in both spatial and temporal dimensions, thereby compensating for exposure deficiencies. To mitigate the impact of inherent sensor noise, a Feature Enhancement Attention (FEA) module bolsters feature robustness against noise via global context modeling. Additionally, a Lightweight Channel-Spatial Attention (LCSA) module is integrated to adaptively recalibrate feature responses while substantially alleviating computational redundancy. These components are optimized by a multidimensional joint loss function—encompassing pixel, feature, and gradient domains—to synergistically enforce multi-scale constraints, ensuring consistency between micro-textures and global topologies. Extensive experiments demonstrate that EFMAN significantly enhances deblurring performance while maintaining efficient inference. Compared to state-of-the-art methods, our approach achieves maximum PSNR and SSIM improvements of 1.19 dB and 0.005 on the GoPro dataset, and 0.38 dB and 0.003 on the REBlur dataset, respectively. By effectively addressing the challenges of multi-modal alignment and noise interference, EFMAN strikes an optimal balance between restoration quality and computational efficiency, making it highly suitable for clear image reconstruction in high-dynamic-range and rapid-motion scenarios.
-
Key words:
- image deblurring /
- event camera /
- multi-modal fusion /
- feature enhancement /
- attention mechanism
-
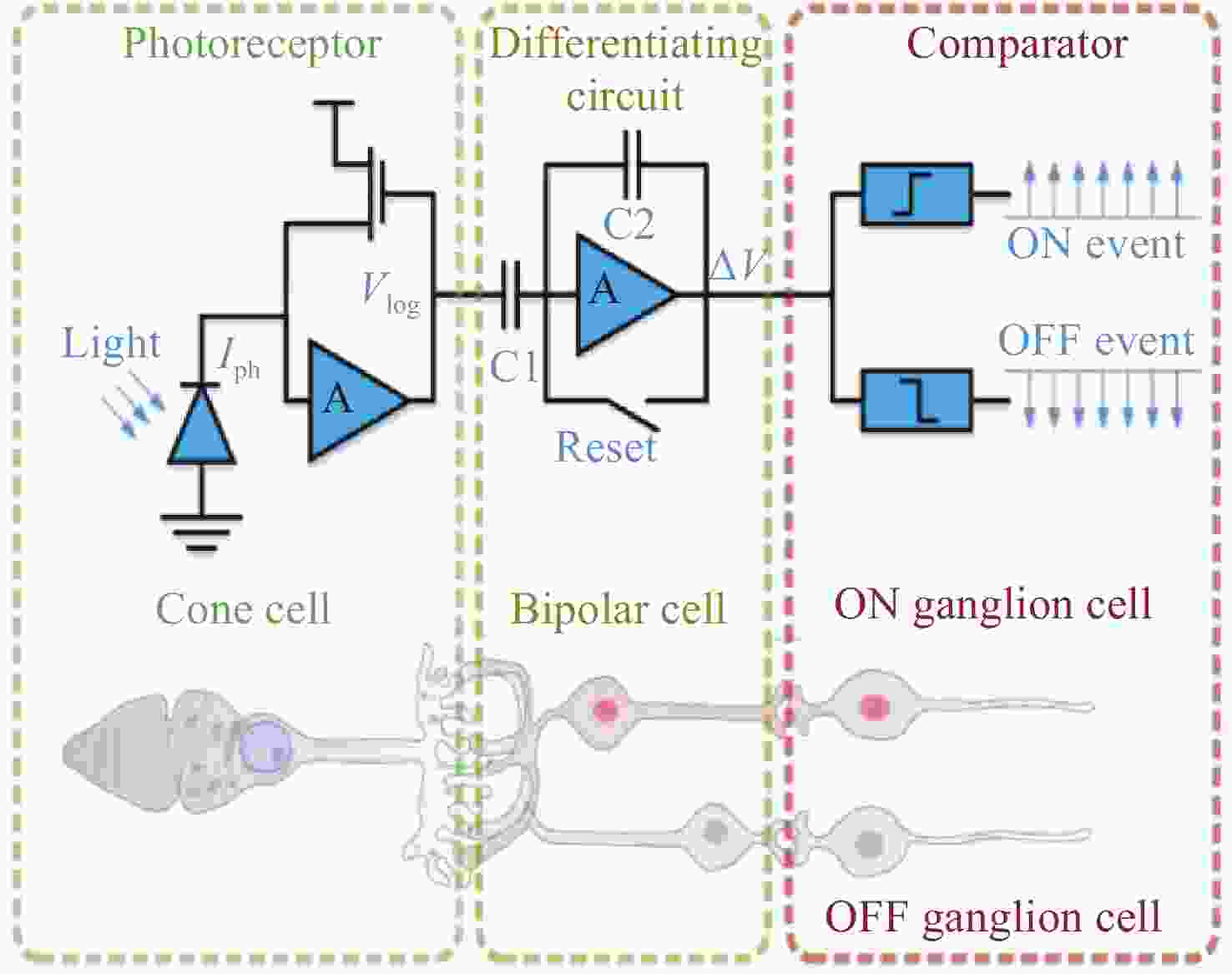
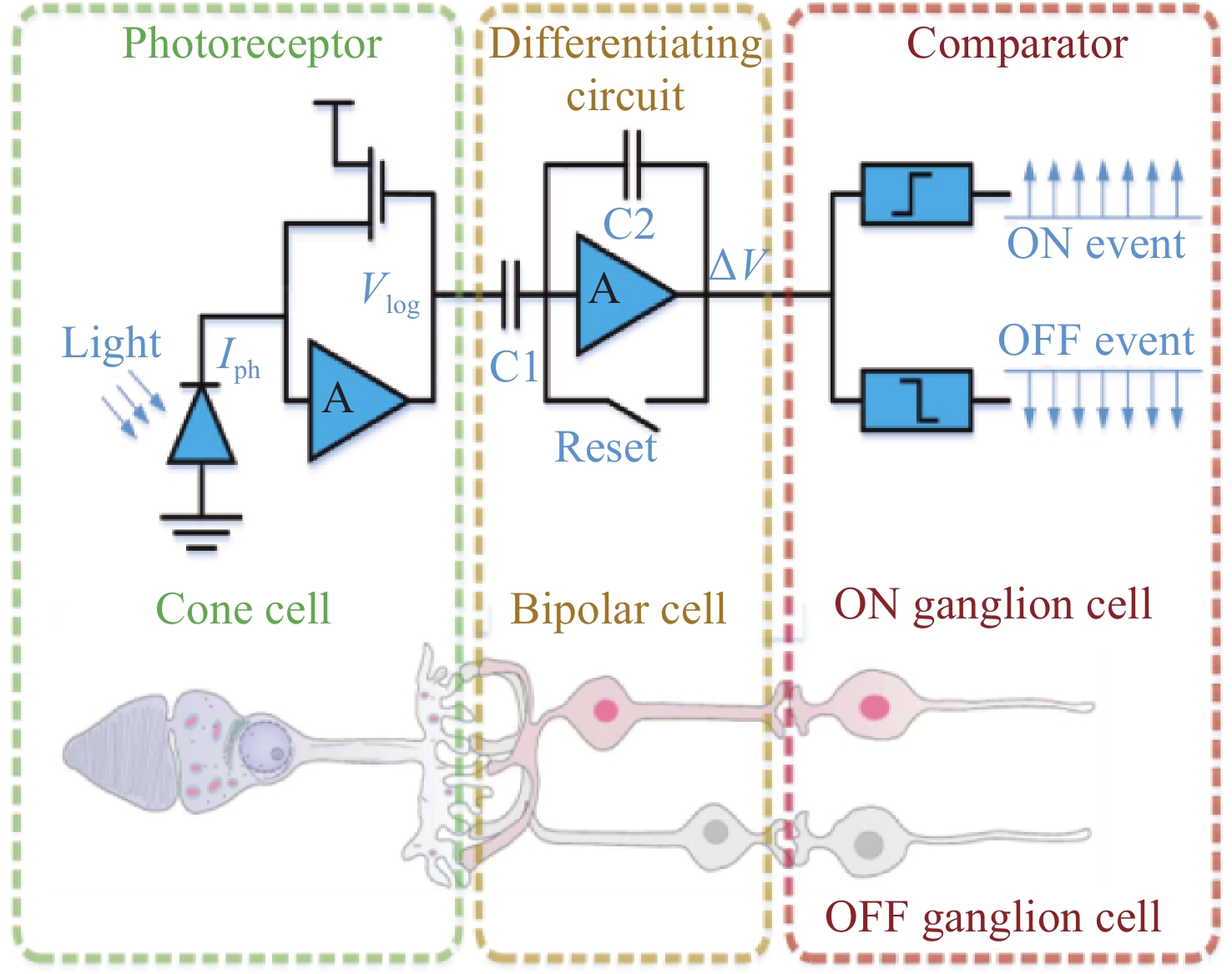
图 1 人眼视网膜三层模型及对应事件相机像素电路
Figure 1. Three-layer model of the human retina and the corresponding pixel circuitry of an event camera
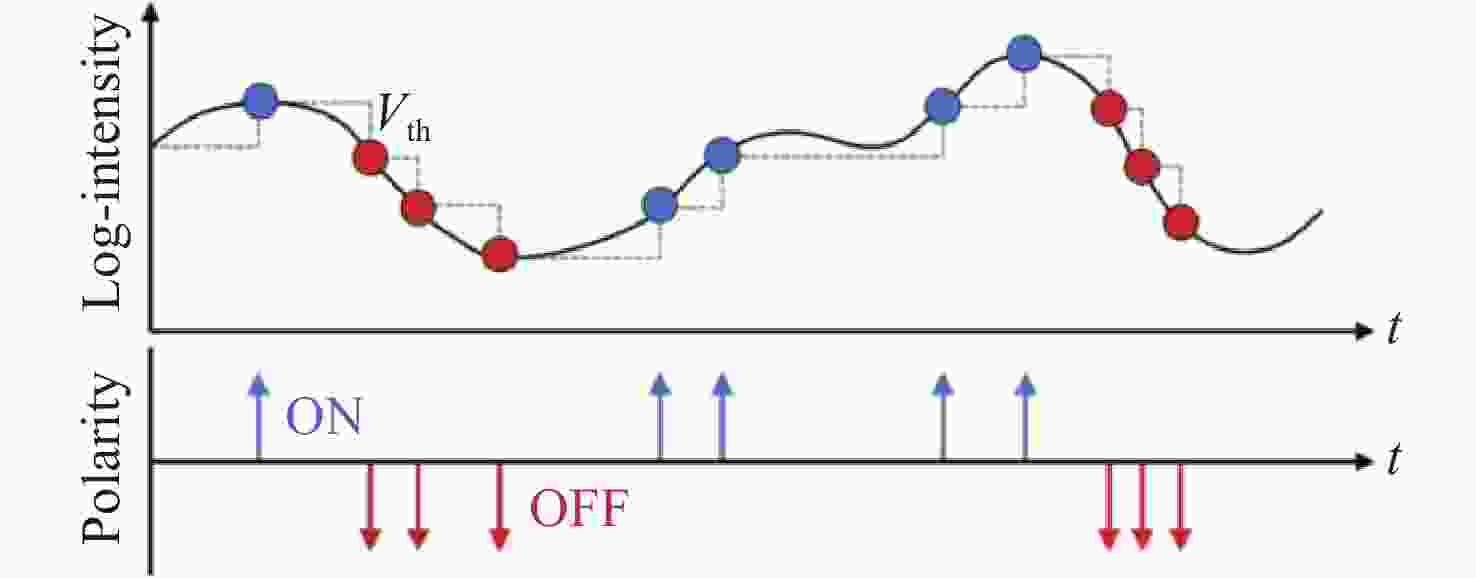
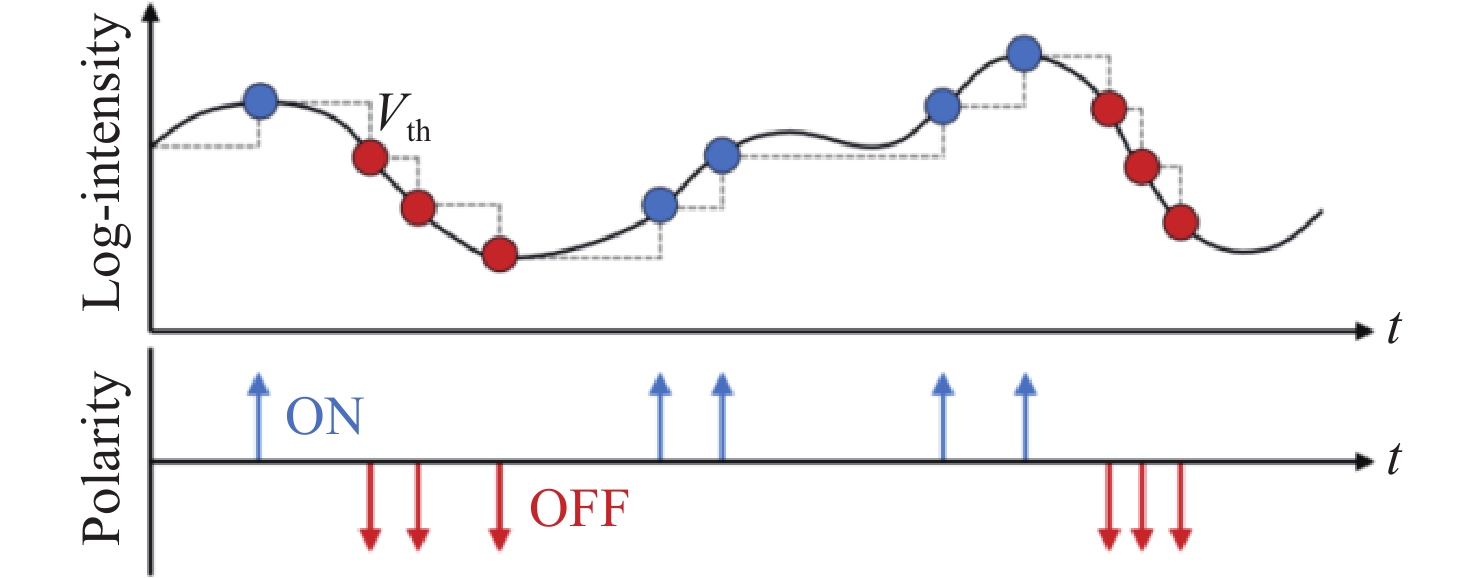
图 2 事件相机生成事件的理论原理
Figure 2. Theoretical mechanism of event generation in event cameras
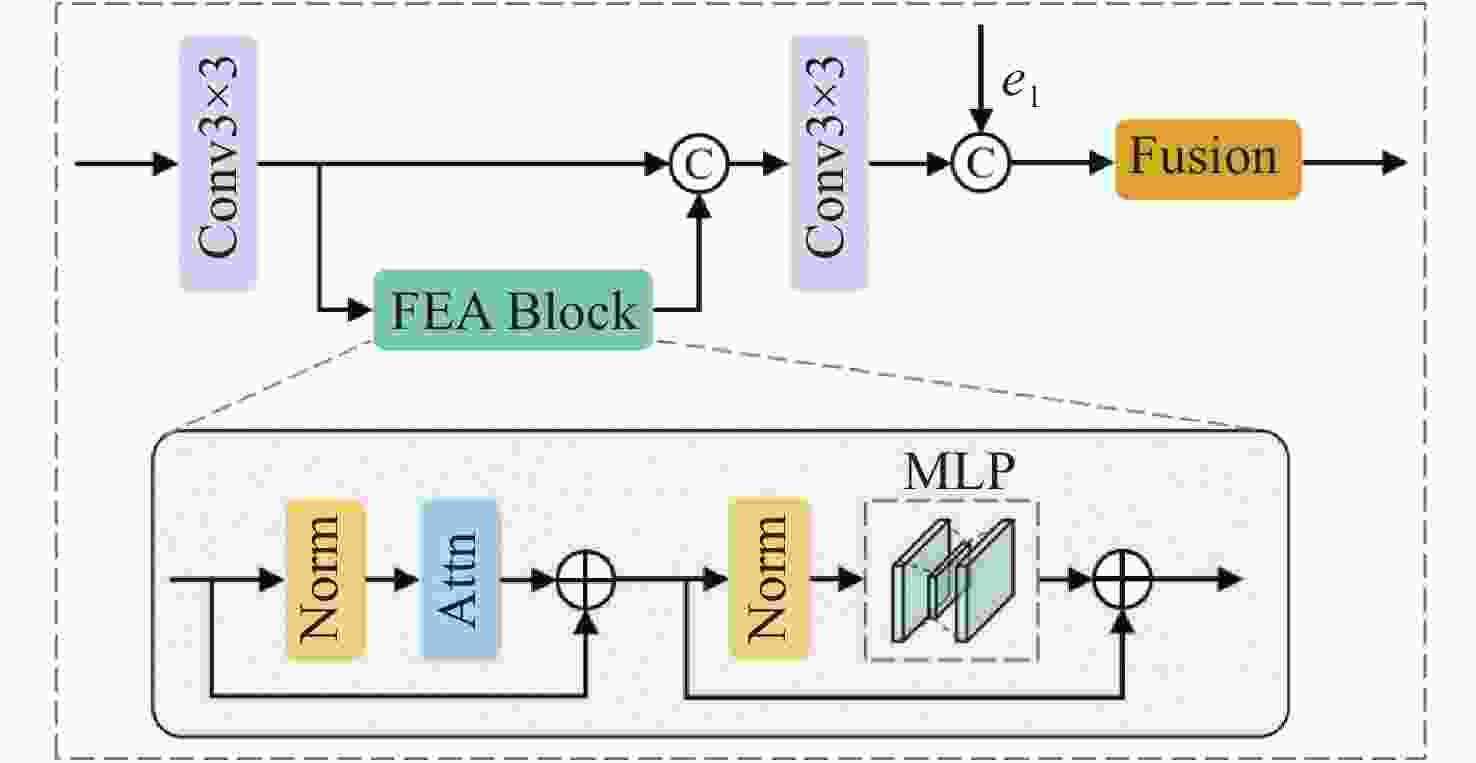
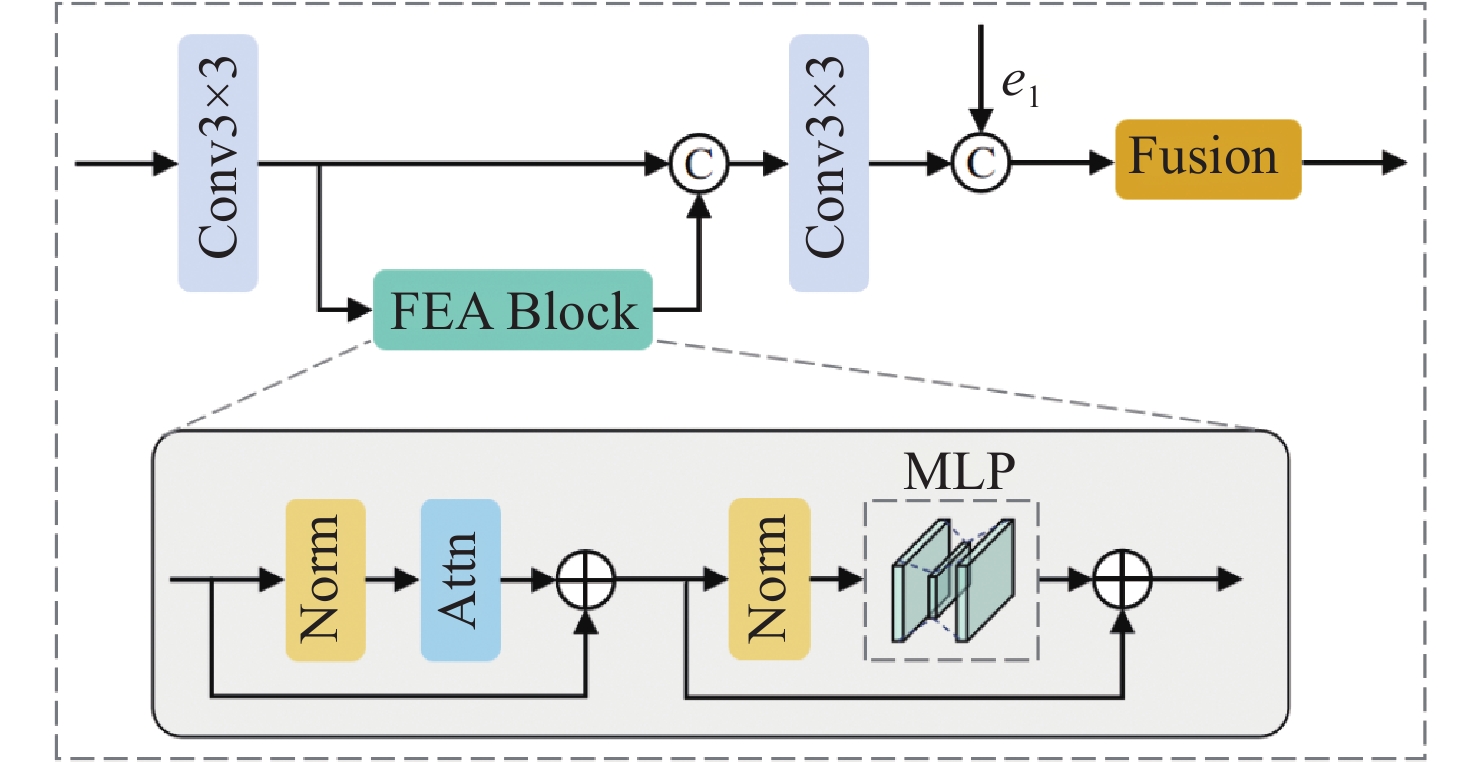
图 4 LA编码器的详细结构(基于FEA模块)
Figure 4. Detailed structure of the LA Encoder (based on the FEA module)
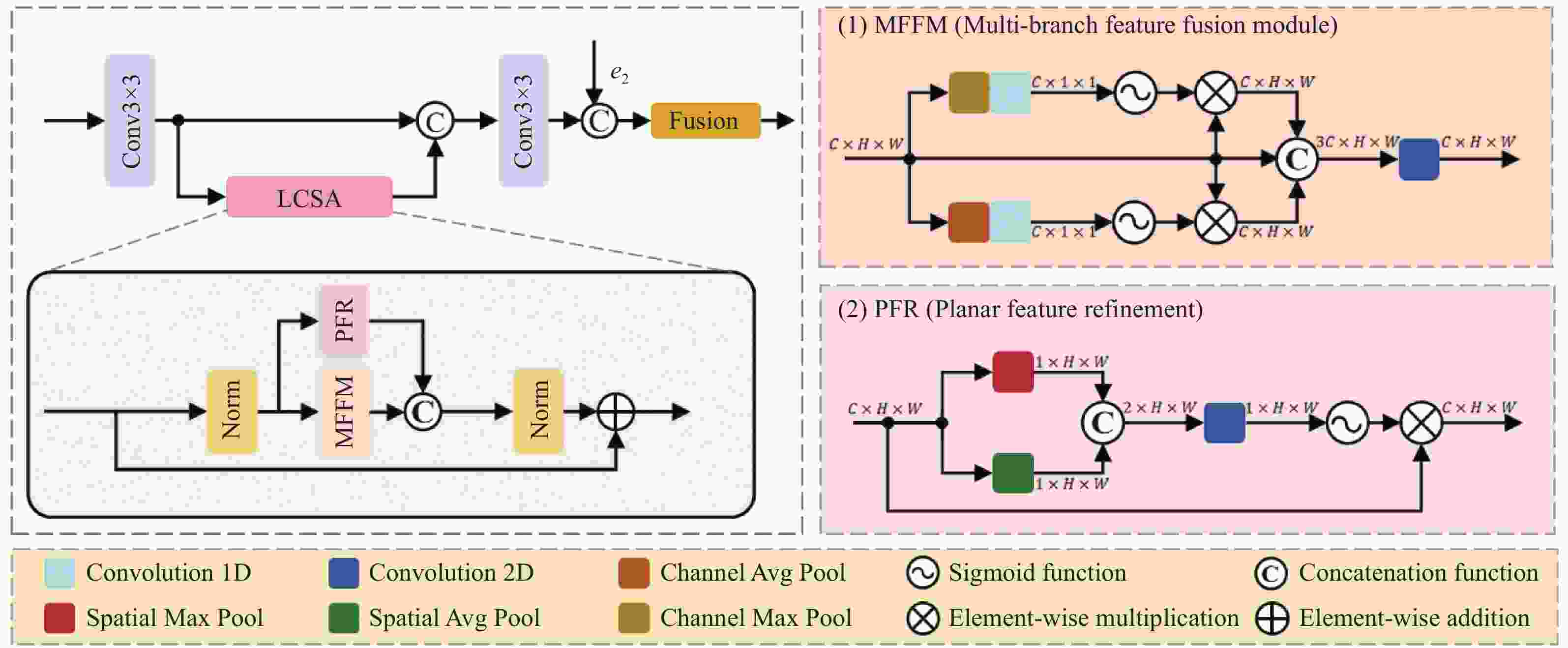
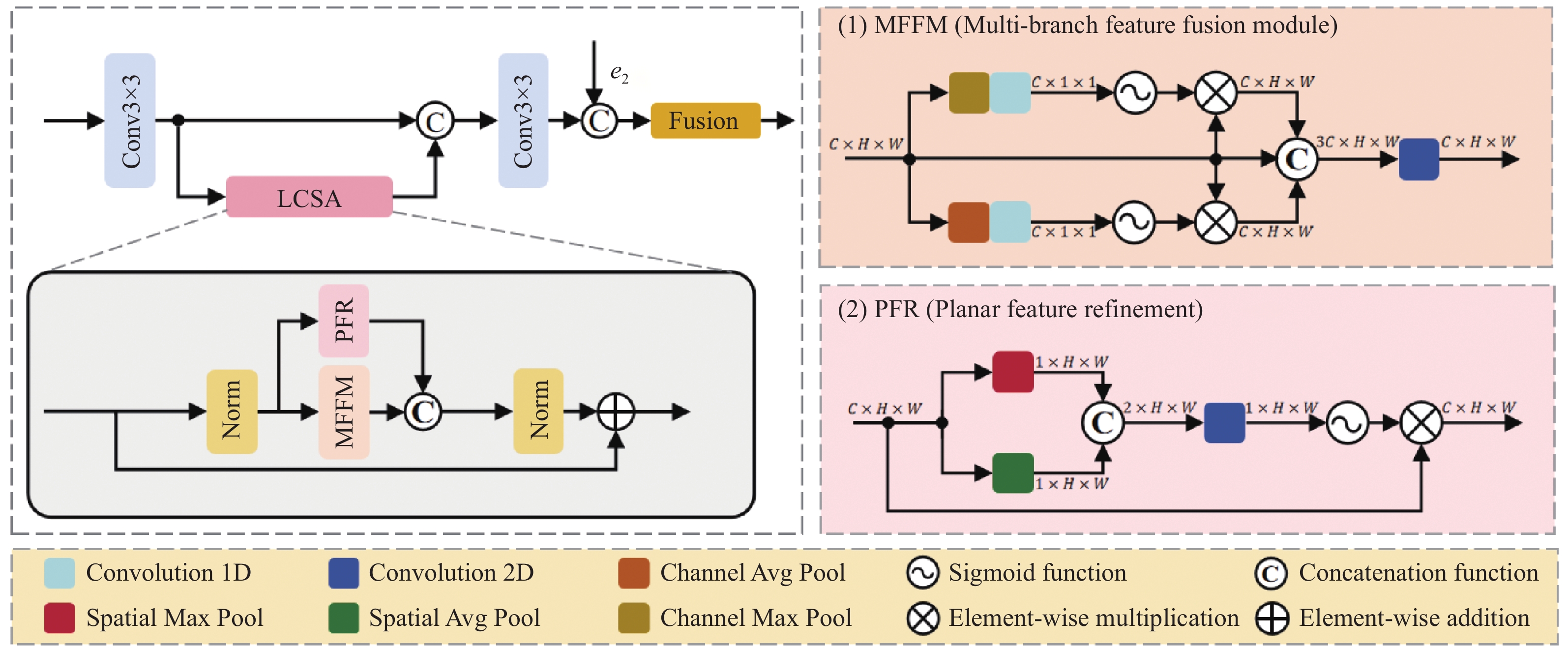
图 5 GA编码器中LCAS模块的架构示意图
Figure 5. Schematic architecture of the LCSA module within the GA Encoder

图 6 各模型在Gopro数据集上的实验效果图
Figure 6. Visual comparison of deblurring results obtained by various models on the GoPro dataset

图 7 各模型在ReBlur数据集上的实验效果图
Figure 7. Visual comparison of deblurring results obtained by various models on the REBlur dataset

图 9 去模糊前后检测效果对比图
Figure 9. Comparison of object detection performance before and after applying the deblurring method
表 1 实验环境配置
Table 1. Configuration of the experimental environment
参数 配置 系统环境 Ubuntu 22.04 显卡 NVIDIA GeForce RTX 3090 深度学习框架 PyTorch 2.1.1 加速环境 CUDA 11.5 和 CuDNN 8.2.0 语言 Python 3.11.5  下载: 导出CSV
下载: 导出CSV
表 2 实验参数配置
Table 2. Configuration of the experimental parameters
参数 数值 图片大小 (Image size) 256×256 训练迭代次数 (Iterations) 200,000 每次更新的批次数 (Batch size) 4 线程数 (Workers) 8 时间 41h
下载: 导出CSV
表 3 各模型在GoPro数据集上的性能对比
Table 3. Quantitative performance comparison of various models on the GoPro dataset
Method Input PSNR SSIM Params(M) FLOPs(G) Inference Time
(ms)Events Image DeblunGAN-v2[33] × √ 29.55 0.934 60.90 41.5 35.2 SRN[35] × √ 30.26 0.934 10.25 52.8 45.1 MPRNet[34] × √ 32.66 0.959 20.10 145.5 78.3 HINet[36] × √ 32.71 0.959 88.67 170.5 85.4 Restormer[17] × √ 32.92 0.961 26.13 140.7 82.1 IRNeXt[37] × √ 33.16 0.962 13.21 32.5 30.8 ChaIR[38] × √ 33.28 0.963 15.02 38.6 36.4 NAFNet[39] × √ 33.69 0.967 67.89 63.2 48.6 FFTformer[40] × √ 34.21 0.969 16.6 45.8 42.3 EFNet[25] √ √ 35.46 0.972 8.47 25.3 24.5 DiffEvent[41] √ √ 35.55 0.972 35.41 210.6 450.5 STCNet[42] √ √ 36.45 0.975 14.35 48.2 38.6 MAENet[17] √ √ 36.07 0.976 12.80 42.1 35.4 EFMAN(ours) √ √ 36.65 0.977 6.59 15.2 28.5
下载: 导出CSV
表 4 各模型在REBlur数据集上对比效果
Table 4. Quantitative performance comparison of various models on the REBlur dataset
Method Input PSNR SSIM Params(M) FLOPs(G) Inference Time (ms) Events Image SRN × √ 35.10 0.961 10.25 52.8 45.1 NAFNet × √ 35.48 0.962 67.89 63.2 48.6 Restormer × √ 35.50 0.959 26.13 140.7 82.1 HINet × √ 35.58 0.965 88.67 170.5 85.4 EFNet √ √ 38.12 0.975 8.47 25.3 24.5 DiffEvent √ √ 38.23 0.974 35.41 210.6 450.5 STCNet √ √ 37.78 0.976 14.35 48.2 38.6 MAENet √ √ 38.46 0.978 12.80 42.1 35.4 EFMAN(ours) √ √ 38.50 0.978 6.59 15.2 28.5
下载: 导出CSV
表 5 消融实验结果
Table 5. Quantitative results of the ablation study
Model Structure PSNR SSIM FEA LCAS Loss CBAM Base × × × × 34.20 0.936 实验A √ × × × 37.31 0.955 实验B × √ × × 37.63 0.967 实验C × × √ × 37.43 0.968 实验D √ × √ √ 37.85 0.972 EFMAN √ √ √ × 38.50 0.978
下载: 导出CSV
表 6 损失函数渐进式消融实验结果
Table 6. Progressive Ablation Study of Loss Functions
优化目标 PSNR SSIM Base(仅含$ {\mathcal{L}}_{pix} $) 34.20 0.936 Base + $ {\mathcal{L}}_{per} $ 35.68 0.948 Base + $ {\mathcal{L}}_{per} $ + $ {\mathcal{L}}_{hf} $ 36.95 0.961 Base + $ {\mathcal{L}}_{per} $ + $ {\mathcal{L}}_{hf} $ + $ {\mathcal{L}}_{tv} $ 37.43 0.968
下载: 导出CSV
表 7 目标检测任务上的定量对比
Table 7. Quantitative performance comparison on the object detection task
Model Car Bus Truck Two-wheel Pedestrian mAP@0.5:0.95 Blur 0.855 0.877 0.723 0.488 0.485 0.743 DiffEvent 0.861 0.874 0.727 0.505 0.478 0.746 STCNet 0.872 0.882 0.726 0.525 0.477 0.747 MAENet 0.868 0.897 0.731 0.529 0.489 0.750 EFMAN (Ours) 0.887 0.905 0.740 0.533 0.505 0.754 Reference 0.895 0.913 0.746 0.536 0.510 0.758
下载: 导出CSV
-
[1] ZHANG K H, REN W Q, LUO W H, et al. Deep image deblurring: a survey[J]. International Journal of Computer Vision, 2022, 130(9): 2103-2130. doi: 10.1007/s11263-022-01633-5 [2] NAH S, KIM T H, LEE K M. Deep multi-scale convolutional neural network for dynamic scene deblurring[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, IEEE, 2017: 257-265. [3] LUO Z W, GUSTAFSSON F K, ZHAO ZH, et al. Image restoration with mean-reverting stochastic differential equations[C]. Proceedings of the 40th International Conference on Machine Learning, JMLR, 2023: 957. [4] LIN X Q, HE J W, CHEN Z Y, et al. DiffBIR: toward blind image restoration with generative diffusion prior[C]. 18th European Conference on Computer Vision – ECCV 2024, Springer, 2024: 430-448. [5] WU H J, ZHANG M Q, HE L CH, et al. Enhancing diffusion model stability for image restoration via gradient management[C]. Proceedings of the 33rd ACM International Conference on Multimedia, Association for Computing Machinery, 2025: 10768-10777. [6] GUO H, LI J M, DAI T, et al. MambaIR: a simple baseline for image restoration with state-space model[C]. 18th European Conference on Computer Vision – ECCV 2024, Springer, 2024: 222-241. [7] LIU Y, TIAN Y J, ZHAO Y ZH, et al. VMamba: visual state space model[C]. Proceedings of the 38th International Conference on Neural Information Processing Systems, Curran Associates Inc., 2024: 3273. [8] ZHU L H, LIAO B CH, ZHANG Q, et al. Vision mamba: efficient visual representation learning with bidirectional state space model[C]. Proceedings of the 41st International Conference on Machine Learning, JMLR, 2024: 2584. [9] LI B Y, ZHAO H Y, WANG W X, et al. MaIR: a locality- and continuity-preserving mamba for image restoration[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, IEEE, 2025: 7491-7501. [10] SHI Y, XIA B, JIN X Y, et al. VmambaIR: visual state space model for image restoration[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2025, 35(6): 5560-5574. doi: 10.1109/TCSVT.2025.3530090 [11] WANG Y F, LIAO K, ZHANG K, et al. Reconfigurable versatile integrated photonic computing chip[J]. eLight, 2025, 5(1): 20. doi: 10.1186/s43593-025-00098-6 [12] FANG X Y, HU X N, LI B L, et al. Orbital angular momentum-mediated machine learning for high-accuracy mode-feature encoding[J]. Light: Science & Applications, 2024, 13(1): 49. [13] GALLEGO G, DELBRUCK T, ORCHARD G, et al. Event-based vision: a survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(1): 154-180. doi: 10.1109/TPAMI.2020.3008413 [14] LICHTSTEINER P, POSCH C, DELBRUCK T. A 128×128 120 dB 15 μs latency asynchronous temporal contrast vision sensor[J]. IEEE Journal of Solid-State Circuits, 2008, 43(2): 566-576. doi: 10.1109/JSSC.2007.914337 [15] 方应红, 徐伟, 朴永杰, 等. 事件视觉传感器发展现状与趋势[J]. 液晶与显示, 2021, 36(12): 1664-1673. doi: 10.37188/CJLCD.2021-0149FANG Y H, XU W, PIAO Y J, et al. Development status and trend of event-based vision sensor[J]. Chinese Journal of Liquid Crystals and Displays, 2021, 36(12): 1664-1673. doi: 10.37188/CJLCD.2021-0149 [16] 柳长源, 曹青, 刘金凤. 遥感图像双模态融合去云方法[J]. 光学 精密工程, 2025, 33(18): 2996-3007. doi: 10.37188/OPE.20253318.2996LIU CH Y, CAO Q, LIU J F. A bimodal fusion method for remote sensing images to cloud removal[J]. Optics and Precision Engineering, 2025, 33(18): 2996-3007. doi: 10.37188/OPE.20253318.2996 [17] CHEN C, SHI H, YANG Y, et al. Uncertainty-aware fusion for event-based deblurring[C]. ACM Multimedia, 2023. (查阅网上资料, 未找到本条文献信息, 请确认). [18] ZHANG X, YU L, YANG W. Unifying motion deblurring and frame interpolation with events[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2022: 17744-17753. [19] SONG CH, HUANG Q X, BAJAJ C. E-CIR: event-enhanced continuous intensity recovery[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2022: 7793-7802. [20] LIN X P, HUANG Y L, REN H W, et al. ClearSight: human vision-inspired solutions for event-based motion deblurring[C]. IEEE/CVF International Conference on Computer Vision, IEEE, 2025: 7462-7471. [21] XIAO Z Y, WANG X CH. Event-based video super-resolution via state space models[C]. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2025: 12564-12574. [22] TULYAKOV S, GEHRIG D, GEORGOULIS S, et al. Time lens: event-based video frame interpolation[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2021: 16150-16159. [23] ZAMIR S W, ARORA A, KHAN S, et al. Restormer: efficient transformer for high-resolution image restoration[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2022: 5718-5729. [24] YAO M, HU J K, ZHOU ZH K, et al. Spike-driven transformer[C]. Proceedings of the 37th International Conference on Neural Information Processing Systems, Curran Associates Inc. , 2023: 2798. [25] SUN L, SAKARIDIS C, LIANG J Y, et al. Event-based fusion for motion deblurring with cross-modal attention[C]. 17th European Conference on Computer Vision – ECCV 2022, Springer, 2022: 412-428. [26] 吕建威, 钱锋, 韩昊男, 等. 结合光源分割和线性图像深度估计的夜间图像去雾[J]. 中国光学, 2022, 15(1): 34-44. doi: 10.37188/CO.2021-0114LV J W, QIAN F, HAN H N, et al. Nighttime image dehazing with a new light segmentation method and a linear image depth estimation model[J]. Chinese Optics, 2022, 15(1): 34-44. doi: 10.37188/CO.2021-0114 [27] SUN L, ALFARANO A, DUAN P Q, et al. NTIRE 2025 challenge on event-based image deblurring: methods and results[C]. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), IEEE, 2025: 1315-1332. [28] LI K CH, LI X H, WANG Y, et al. VideoMamba: state space model for efficient video understanding[C]. 18th European Conference on Computer Vision – ECCV 2024, Springer, 2024: 237-255. [29] WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]. 15th European Conference on Computer Vision – ECCV 2018, Springer, 2018: 3-19. [30] 王慧, 曹召良, 王军. 改进丰富卷积特征算法的液滴边缘检测模型[J]. 中国光学(中英文), 2024, 17(4): 886-895. doi: 10.37188/CO.2024-0019WANG H, CAO ZH L, WANG J. Improved droplet edge detection model based on RCF algorithm[J]. Chinese Optics, 2024, 17(4): 886-895. doi: 10.37188/CO.2024-0019 [31] 贺兴, 王磊, 张鹏超, 等. 基于多维注意力网络的图像超分辨率重建[J]. 液晶与显示, 2025, 40(7): 1056-1066. doi: 10.37188/CJLCD.2025-0058HE X, WANG L, ZHANG P CH, et al. Image super-resolution reconstruction based on multidimensional attention network[J]. Chinese Journal of Liquid Crystals and Displays, 2025, 40(7): 1056-1066. doi: 10.37188/CJLCD.2025-0058 [32] PAN L Y, SCHEERLINCK C, YU X, et al. Bringing a blurry frame alive at high frame-rate with an event camera[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2019: 6813-6822. [33] KUPYN O, MARTYNIUK T, WU J R, et al. DeblurGAN-v2: deblurring (orders-of-magnitude) faster and better[C]. 2019 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE, 2019: 8877-8886. [34] ZAMIR S W, ARORA A, KHAN S, et al. Multi-stage progressive image restoration[C]. IEEE Conference on Computer Vision and Pattern Recognition, IEEE, 2021: 14821-14831. [35] TAO X, GAO H Y, SHEN X Y, et al. Scale-recurrent network for deep image deblurring[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, IEEE, 2018: 8174-8182. [36] CHEN L Y, LU X, ZHANG J, et al. HINet: half instance normalization network for image restoration[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), IEEE, 2021: 182-192. [37] CUI Y N, REN W Q, YANG S N, et al. IRNeXt: rethinking convolutional network design for image restoration[C]. Proceedings of the 40th International Conference on Machine Learning, PMLR, 2023: 6545-6564. [38] CUI Y N, KNOLL A. Exploring the potential of channel interactions for image restoration[J]. Knowledge-Based Systems, 2023, 282: 111156. doi: 10.1016/j.knosys.2023.111156 [39] CHEN L Y, CHU X J, ZHANG X Y, et al. Simple Baselines for Image Restoration[C]. 17th European Conference on Computer Vision – ECCV 2022, Springer, 2022: 17-33. [40] KONG L, DONG X, ZHANG J, et al. FFTformer: toward efficient image restoration via frequency domain learning[C]. CVPR, 2023. (查阅网上资料, 未找到本条文献信息, 请确认). [41] WANG P, HE J M, YAN Q S, et al. DiffEvent: event residual diffusion for image deblurring[C]. ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2024: 3450-3454. [42] YANG W, WU J J, MA J P, et al. Motion deblurring via spatial-temporal collaboration of frames and events[C]. Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI, 2024: 726. [43] SUN ZH J, FU X Y, HUANG L ZH, et al. Motion aware event representation-driven image deblurring[C]. 18th European Conference on Computer Vision – ECCV 2024, Springer, 2024: 418-435. [44] JING SH L, LV H Y, ZHAO Y CH, et al. Hyper lightweight neural networks towards spike-driven deep residual learning[J]. Knowledge-Based Systems, 2025, 327: 114099. doi: 10.1016/j.knosys.2025.114099 -

 下载:
下载:





计量
- 文章访问数: 208
- HTML全文浏览量: 101
- PDF下载量: 4
- 被引次数: 0
