


-
摘要: 针对现有方法处理包含多个显著目标以及显著目标的某些区域与背景区域对比不明显的场景所得显著图不够精细,甚至会丢失某些显著性区域的不足,本文提出了一种结合相机阵列选择性光场重聚焦的显著性检测方法。选用光场数据集,利用同一场景的多幅视点图像,首先对中心视点图像进行结合超分辨率的重聚焦渲染;然后利用基于图的显著性检测方法提出结合全局和局部平滑度约束的传播模型以防止错误标签传播,得到的显著性粗图经过目标图的细化后最终输出精细的检测结果。另外,对于包含多个显著目标的场景,通过选择对场景中某一深度层进行重聚焦,同时对其他深度层产生不同程度的模糊,可以更精确、细致地检测出位于该深度层上的显著目标,一定程度上实现了可选择的显著性检测。在4D光场数据集上进行了实验,结果表明:本文提出的方法所得显著图与真值图之间的平均绝对误差的均值为0.212 8,较现有方法有所降低,检测结果包含更丰富的显著性目标信息,改善了现有显著性检测方法的不足。Abstract: For the multiple salient targets scene, as well as a scene in which some areas of the salient target do not contrast significantly with the background area, the saliency maps obtained by existing algorithms are not fine enough or even lose some saliency regions. In this paper, a new saliency detection method combined with selective light field refocusing of camera array is proposed. In this method, the light field dataset is selected and multi-viewpoint images of the same scene are used. First, we perform refocusing rendering combined with super-resolution on the central viewpoint image. Then, on the basis of the graph-based saliency detection method, we propose a propagation model combining global and local smoothness constraints to prevent false label propagation. Finally, the obtained coarse saliency map is refined through the object map to output the final saliency map. In addition, for the scene that contains multiple salient targets, by refocusing a certain depth layer in the scene, and producing varying degrees of blurring to other depth layers, the salient targets on the depth layer can be detected accurately and in detail. To a certain extent, the optional saliency detection is realized. Experiments on the 4D light field dataset show that the average Mean Absolute Error (MAE) between the ground truth and the saliency map obtained by the method proposed in this paper is 0.2128, which is lower than those obtained by the existing methods. The detection result contains more detailed information about the salient target, which improves the above-mentioned shortcomings of the existing salient detection methods.
-
Key words:
- camera array /
- refocusing /
- saliency detection
-
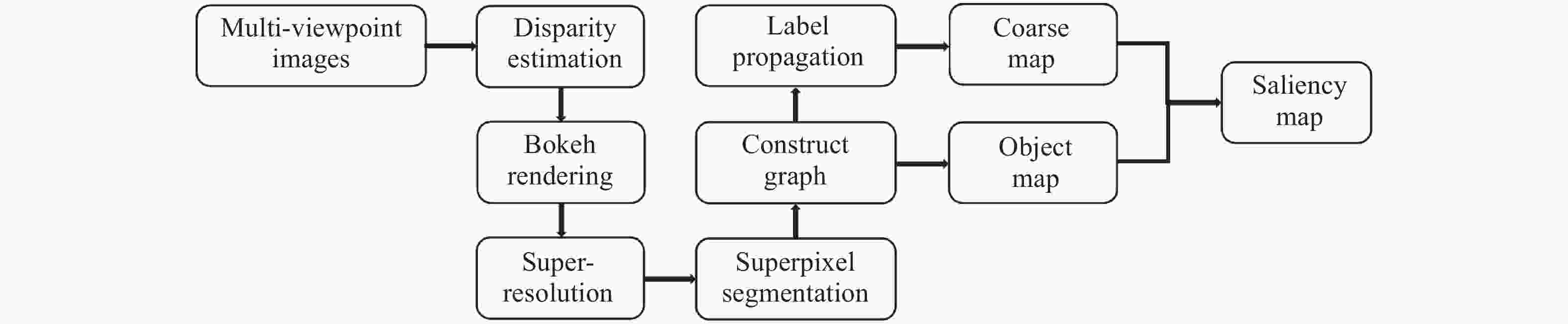
图 1 结合相机阵列选择性光场重聚焦的显著性检测算法的框架图
Figure 1. Framework diagram of the saliency detection algorithm combined with selective light field refocusing of camera array

图 2 聚焦于场景不同深度层上的重聚焦结果
Figure 2. Refocusing results focusing on different depth layers of the scene

图 3 5种算法对场景Table和Boxes进行显著性检测所得结果比较
Figure 3. Comparison of the saliency detection results obtained by five algorithms for the scene Table and Boxes

图 4 本文算法所得结果与最新的基于深度学习的显著性目标检测算法所得结果的比较
Figure 4. The comparison between the results of our algorithm and the latest salient object detection algorithm based on deep learning

图 5 聚焦于场景不同深度层所得显著图比较
Figure 5. Comparison of saliency maps obtained by focusing on different depth layers of the scene
-
[1] MANISHA P, JAYADEVAN R, SHEEBA V S. Content-based image retrieval through semantic image segmentation[J]. AIP Conference Proceedings, 2020, 2222(1): 030008. [2] 叶润春. 显著性检测的优化模型及在图像压缩中的应用[D]. 合肥: 中国科学技术大学, 2018.YE R CH. A model of optimizing saliency detection and its application in image compression[D]. Hefei: University of Science and Technology of China, 2018. (in Chinese). [3] 王超. 基于立体视觉的目标识别与跟踪研究[D]. 大连: 大连理工大学, 2019.WANG CH. Research on target recognition and tracking based on stereo vision[D]. Dalian: Dalian University of Technology, 2019. (in Chinese). [4] 丁晨. 显著性检测与结构相似相结合的图像融合算法[D]. 西安: 陕西师范大学, 2019.DING CH. A image fusion algorithm combining saliency detection and structural similarity[D]. Xi’an: Shaanxi Normal University, 2019. (in Chinese) [5] GALIANO G, RAMÍREZ I, SCHIAVI E. Non-convex non-local reactive flows for saliency detection and segmentation[J]. Journal of Computational and Applied Mathematics, 2020, 377: 112873. doi: 10.1016/j.cam.2020.112873 [6] 崔丽群, 吴晓冬, 赵越. 基于CRF-MR的自顶向下显著性目标检测方法[J]. 计算机应用研究,2018,35(8):2535-2539. doi: 10.3969/j.issn.1001-3695.2018.08.074CUI L Q, WU X D, ZHAO Y. Top-down saliency target detection dased on CRF-MR[J]. Application Research of Computers, 2018, 35(8): 2535-2539. (in Chinese) doi: 10.3969/j.issn.1001-3695.2018.08.074 [7] 程藜, 吴谨, 朱磊. 基于结构标签学习的显著性目标检测[J]. 液晶与显示,2016,31(7):726-732. doi: 10.3788/YJYXS20163107.0726CHENG L, WU J, ZHU L. Salient object detection based on structured labels learning[J]. Chinese Journal of Liquid Crystals and Displays, 2016, 31(7): 726-732. (in Chinese) doi: 10.3788/YJYXS20163107.0726 [8] 杜杰, 吴谨, 朱磊. 基于区域特征融合的RGBD显著目标检测[J]. 液晶与显示,2016,31(1):117-123. doi: 10.3788/YJYXS20163101.0117DU J, WU J, ZHU L. RGBD salient object detection based on regional feature integration[J]. Chinese Journal of Liquid Crystals and Displays, 2016, 31(1): 117-123. (in Chinese) doi: 10.3788/YJYXS20163101.0117 [9] YAN Y J, REN J CH, SUN G Y, et al. Unsupervised image saliency detection with gestalt-laws guided optimization and visual attention based refinement[J]. Pattern Recognition, 2018, 79: 65-78. doi: 10.1016/j.patcog.2018.02.004 [10] WU ZH, SU L, HUANG Q M. Cascaded partial decoder for fast and accurate salient object detection[C]. Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2019: 3907-3916. [11] ACHANTA R, ESTRADA F, WILS P, et al.. Salient region detection and segmentation[C]. Proceedings of the 6th International Conference on Computer Vision Systems (ICVS), Springer, 2008: 66-75. [12] CHENG M M, ZHANG G X, MITRA N J, et al.. Global contrast based salient region detection[C]. Proceedings of 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2011: 409-416. [13] GOFERMAN S, ZELNIK-MANOR L, TAL A. Context-aware saliency detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(10): 1915-1926. doi: 10.1109/TPAMI.2011.272 [14] FU K R, GONG CH, YANG J, et al. Superpixel based color contrast and color distribution driven salient object detection[J]. Image Communication, 2013, 28(10): 1448-1463. [15] 孙君顶, 张毅, 李海华. 融合高低层多特征的显著性检测算法[J]. 液晶与显示,2019,34(4):430-438. doi: 10.3788/YJYXS20193404.0430SUN J D, ZHANG Y, LI H H. Saliency detection algorithm integrating multiple features of high and low level[J]. Chinese Journal of Liquid Crystals and Displays, 2019, 34(4): 430-438. (in Chinese) doi: 10.3788/YJYXS20193404.0430 [16] YANG CH, ZHANG L H, LU H CH, et al.. Saliency detection via graph-based manifold ranking[C]. Proceedings of 2013 IEEE Conference on Computer Vision and Pattern Recognition, IEEE, 2013: 3166-3173. [17] WU X Y, MA X D, ZHANG J X, et al. Salient object detection via reliable boundary seeds and saliency refinement[J]. IET Computer Vision, 2019, 13(3): 302-311. doi: 10.1049/iet-cvi.2018.5013 [18] LI CH Y, YUAN Y CH, CAI W D, et al.. Robust saliency detection via regularized random walks ranking[C]. Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2015: 2710-2717. [19] WU X Y, MA X D, ZHANG J X, et al.. Salient object detection via deformed smoothness constraint[C]. Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), IEEE, 2018: 2815-2819. [20] XING Y, WANG Q H, REN H, et al. Optical arbitrary-depth refocusing for large-depth scene in integral imaging display based on reprojected parallax image[J]. Optics Communications, 2019, 433: 209-214. doi: 10.1016/j.optcom.2018.10.022 [21] WANG Y Q, YANG J G, GUO Y L, et al. Selective light field refocusing for camera arrays using bokeh rendering and superresolution[J]. IEEE Signal Processing Letters, 2019, 26(1): 204-208. doi: 10.1109/LSP.2018.2885213 [22] WANG Y Q, YANG J G, MO Y, et al. Disparity estimation for camera arrays using reliability guided disparity propagation[J]. IEEE Access, 2018, 6: 21840-21849. doi: 10.1109/ACCESS.2018.2827085 [23] FARSIU S, ROBINSON M D, ELAD M, et al. Fast and robust multiframe super resolution[J]. IEEE Transactions on Image Processing, 2004, 13(10): 1327-1344. doi: 10.1109/TIP.2004.834669 [24] LEE S, KIM G J, CHOI S. Real-time depth-of-field rendering using point splatting on per-pixel layers[J]. Computer Graphics Forum, 2008, 27(7): 1955-1962. doi: 10.1111/j.1467-8659.2008.01344.x [25] ACHANTA R, SHAJI A, SMITH K, et al. SLIC superpixels compared to state-of-the-art superpixel methods[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(11): 2274-2282. doi: 10.1109/TPAMI.2012.120 [26] FREY B J, DUECK D. Clustering by passing messages between data points[J]. Science, 2007, 315(5814): 972-976. doi: 10.1126/science.1136800 [27] ZITNICK C L, DOLLÁR P. Edge boxes: locating object proposals from edges[C]. Proceedings of the 13th European Conference on Computer Vision (ECCV), Springer, 2014: 391-405. [28] HONAUER K, JOHANNSEN O, KONDERMANN D, et al.. A dataset and evaluation methodology for depth estimation on 4D light fields[C]. Proceedings of the 13th Asian Conference on Computer Vision (ACCV), Springer, 2016: 19-34. -

 下载:
下载:






计量
- 文章访问数: 2147
- HTML全文浏览量: 780
- PDF下载量: 100
- 被引次数: 0
