


Self-supervised learning enhancement and detection methods for nocturnal animal images
-
摘要:
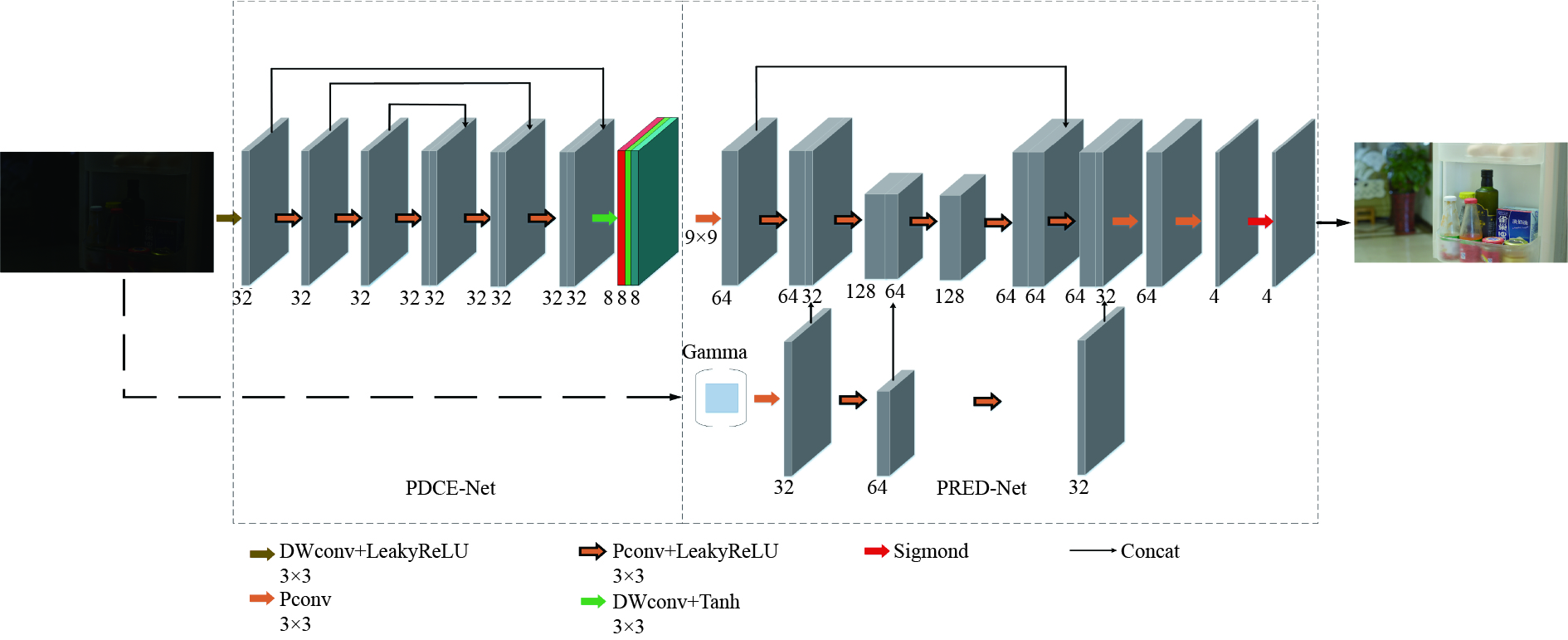
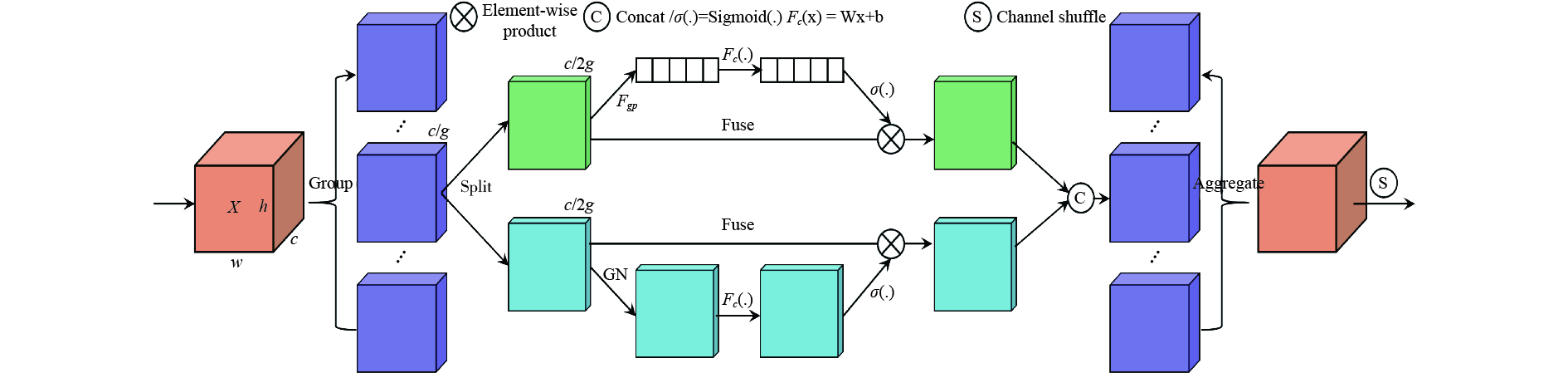
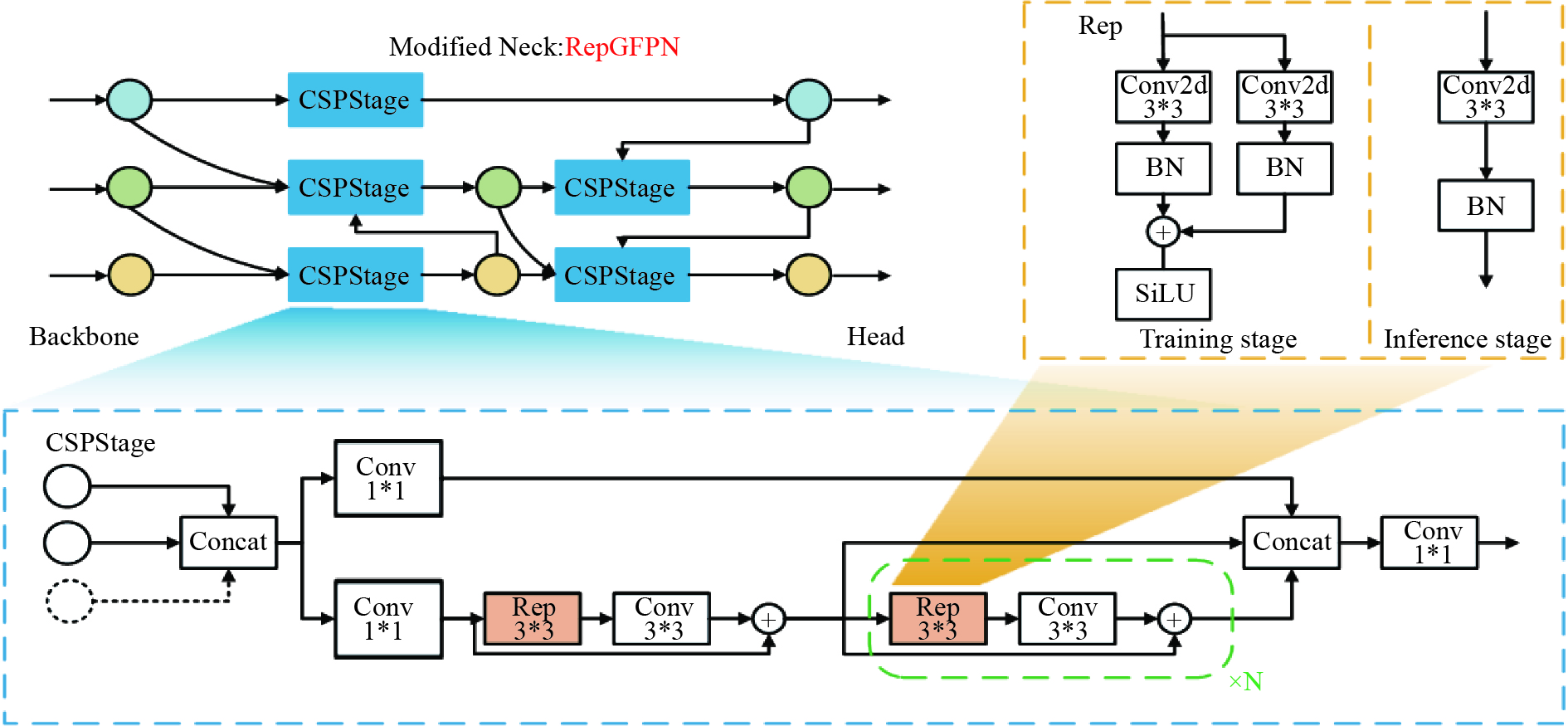
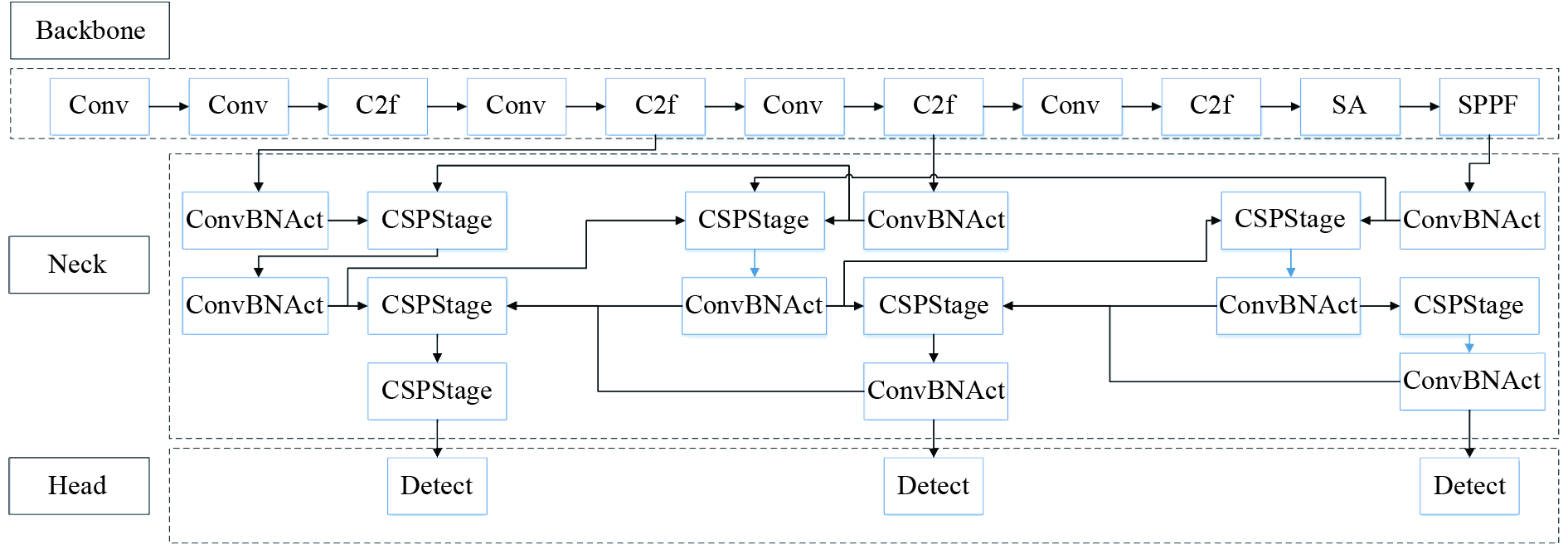
为了解决动物夜间实时监测所面临的图像曝光度低、对比度低、特征提取困难等问题,通过研究轻量化自监督深度神经网络Zero-Denoise和改进型YOLOv8模型,来进行夜间动物目标的图像增强与精准识别。首先,通过轻量化的PDCE-Net进行第一阶段快速增强。提出了一个新的光照损失函数,并利用参数可调的Gamma校正原图与快速增强图,在基于Retinex原理和最大熵理论的PRED-Net中进行第二阶段的重增强。然后,改进YOLOv8模型,并对重增强后的图像进行目标识别。最后,在LOL数据集(low-light dataset)与自建动物数据集进行实验分析,验证Zero-Denoise网络和改进型YOLOv8模型对于夜间动物目标监测的改善效果。试验结果显示,Zero-Denoise的mAP值网络在 LOL 数据集上的PSNR、SSIM与MAE指标达到28.53、0.76、26.15,结合改进型 YOLOv8 在自建动物数据集上的mAP值比 YOLOv8 基线模型提升了7.1%。使用 Zero-Denoise和改进型YOLOv8能获得良好的夜间动物目标图像。结果表明所提方法可用于夜间动物目标的精确监测。
Abstract:In order to solve the problems of low image exposure, low contrast and difficulty of feature extraction in real-time animal monitoring at night, we proposed a lightweight self-supervised deep neural network Zero-Denoise and an improved YOLOv8 model for image enhancement and accurate recognition of nocturnal animal targets. The first stage of rapid enhancement was performed by lightweight PDCE-Net. A new lighting loss function was proposed, and the second stage of re-enhancement was carried out in PRED-Net based on the Retinex principle and the maximum entropy theory, using the original image and fast enhancement image corrected by the parameter adjustable Gamma. Then, the YOLOv8 model was improved to recognize the re-enhanced image. Finally, experimental analysis was conducted on the LOL dataset and the self-built animal dataset to verify the improvement of the Zero-Denoise network and YOLOv8 model for nocturnal animal target monitoring. The experimental results show that the PSNR, SSIM, and MAE indicators of the Zero-Denoise network on the LOL dataset reach 28.53, 0.76, and 26.15, respectively. Combined with the improved YOLOv8, the mAP value of the baseline model on the self-built animal dataset increases by 7.1% compared to YOLOv8. Zero-Denoise and improved YOLOv8 can achieve good quality images of nocturnal animal targets, which can be helpful in further study of accurate methods of monitoring these targets.
-

图 7 各类先进图像增强算法对比
Figure 7. Performance comparison of various advanced image enhancement algorithms

图 8 增强与未增强的目标检测可视化结果
Figure 8. Visualization results of enhanced and unenhanced target detection
表 1 不同算法评价结果
Table 1. Evaluation results of different algorithms
算法 PSNR SSIM MAE Runtime(s) 无监督
自监督Zero-DCE ++ 27.93 0.5725 44.9393 0.0008 SCI 27.90 0.5254 48.7550 0.000 6 Zero-Denoise(ours) 28.53 0.766 5 26.151 6 0.0181 有监督 StableLLVE 27.92 0.7373 32.4789 0.5900 URetinex-Net 28.45 0.833 2 21.156 2 0.0367 Retinexnet 28.06 0.4250 32.0174 0.1200 MBLLEN 28.04 0.7247 31.2498 8.5633 Zero-Denoise(ours) 28.53 0.7665 26.1516 0.018 1  下载: 导出CSV
下载: 导出CSV
表 2 改进YOLOv8消融实验结果
Table 2. Experimental results of improved YOLOv8 ablation
算法 改进主干 改进颈部 改进损失 P R mAP@0.5 mAP@0.5:0.95 YOLOv8 72.3 70.8 80.7 49.7 A √ 73.3(+1.0%) 72.3(+1.5%) 81.2(+0.5%) 50.3(+0.6%) B √ 75.0(+2.7%) 74.6(+3.8%) 81.4(+0.7%) 50.4(+0.7%) C √ 73.3 72.3(+1.5%) 80.9(+0.2%) 50.1(+0.4%) D √ √ 76.0(+3.7%) 74.9(+4.1%) 81.9(+1.2%) 51.3(+1.4%) Ours √ √ √ 77.9(+5.6%) 75.2(+5.6%) 82.2(+1.5%) 51.7+(2.0%)
下载: 导出CSV
表 3 不同算法对改进YOLOv8的效果
Table 3. The effect of different algorithms on improved YOLOv8
算法 Rabbit Bird Chicken Mouse Duck mAP@0.5 Im-YOLOv8 94.0 86.5 62.2 80.3 63.5 82.2 URetinex-Net+Im-YOLOv8 94.5 88.0 73.5 91.9 66.2 83.5(+1.3%) StableLLVE+Im-YOLOv8 93.5 90.6 71.6 82.2 64.5 82.5(+0.3%) SCI+Im-YOLOv8 94.7 91.1 72.0 93.2 69.5 84.7(+2.5%) Retinexnet+Im-YOLOv8 89.2 76.6 60.9 68.5 58.7 78.5(-3.7%) MBLLEN+Im-YOLOv8 94.2 90.8 72.5 89.0 65.5 83.1(+1.1%) Zero-Denoise+Im-YOLOv8 95.0 91.7 74.6 97.4 76.0 87.8(+5.6%)
下载: 导出CSV
表 4 增强与未增强的目标检测可视化结果对比
Table 4. Visualization results comparison of enhanced and unenhanced target detection
组别 应检个数/实检个数 检测精度 结论 a鸽类增强后检测结果 3/3 0.49/0.79/0.89 未增强图像出现漏检数量1,阴影处鸽类未检出 b鸽类未增强检测结果 3/2 0.00/0.81/0.88 c鸡类增强后检测结果 6/6 0.55/0.80/0.81/0.85/0.57/0.46 未增强图像出现漏检数量2,角落处和被遮挡的鸡类未检出 d鸡类未增强检测结果 6/4 0.00/0.84/0.89/0.83/0.85/0.00 e鸭类增强后检测结果 3/3 0.50/0.86/0.81 未增强图像出现漏检数量1,深处的鸭类未检出 f鸭类未增强检测结果 3/2 0.00/0.71/0.68 g鸭类增强后检测结果 4/4 0.27/0.66/0.82/0.36 未增强图像出现漏检数量2,左侧和右侧阴影内鸭类未检出 h鸭类未增强检测结果 4/2 0.00/0.31/0.88/0.00 i鼠类增强后检测结果 4/4 0.87/0.82/0.88/0.80 增强图像中鼠类检测精度提升明显,从0.27、0.26提升至0.82、0.80 j鼠类未增强检测结果 4/4 0.83/0.27/0.87/0.26 k兔类增强后检测结果 1/1 0.90 增强图像中兔类检测精度提升明显,从0.77提升至0.90 l兔类未增强检测结果 1/1 0.77
下载: 导出CSV
-
[1] QI Y L, YANG ZH, SUN W H, et al. A comprehensive overview of image enhancement techniques[J]. Archives of Computational Methods in Engineering, 2022, 29(1): 583-607. doi: 10.1007/s11831-021-09587-6 [2] 刘彦磊, 李孟喆, 王宣宣. 轻量型YOLOv5s车载红外图像目标检测[J]. 中国光学(中英文),2023,16(5):1045-1055. doi: 10.37188/CO.2022-0254LIU Y L, LI M ZH, WANG X X. Lightweight YOLOv5s vehicle infrared image target detection[J]. Chinese Optics, 2023, 16(5): 1045-1055. (in Chinese). doi: 10.37188/CO.2022-0254 [3] HU H F. Illumination invariant face recognition based on dual-tree complex wavelet transform[J]. IET Computer Vision, 2015, 9(2): 163-173. doi: 10.1049/iet-cvi.2013.0342 [4] MUNIAN Y, MARTINEZ-MOLINA A, MISERLIS D, et al. Intelligent system utilizing HOG and CNN for thermal image-based detection of wild animals in nocturnal periods for vehicle safety[J]. Applied Artificial Intelligence, 2022, 36(1): 2031825. doi: 10.1080/08839514.2022.2031825 [5] MURUGAN R A, SATHYABAMA B. Object detection for night surveillance using Ssan dataset based modified Yolo algorithm in wireless communication[J]. Wireless Personal Communications, 2023, 128(3): 1813-1826. doi: 10.1007/s11277-022-10020-9 [6] BHATT D, PATEL C, TALSANIA H, et al. CNN variants for computer vision: history, architecture, application, challenges and future scope[J]. Electronics, 2021, 10(20): 2470. doi: 10.3390/electronics10202470 [7] 任凤雷, 周海波, 杨璐, 等. 基于双注意力机制的车道线检测[J]. 中国光学(中英文),2023,16(3):645-653. doi: 10.37188/CO.2022-0033REN F L, ZHOU H B, YANG L, et al. Lane detection based on dual attention mechanism[J]. Chinese Optics, 2023, 16(3): 645-653. (in Chinese). doi: 10.37188/CO.2022-0033 [8] LI CH Y, GUO J CH, PORIKLI F, et al. LightenNet: a Convolutional Neural Network for weakly illuminated image enhancement[J]. Pattern Recognition Letters, 2018, 104: 15-22. doi: 10.1016/j.patrec.2018.01.010 [9] DING X, HU R M. Learning to see faces in the dark[C]. 2020 IEEE International Conference on Multimedia and Expo (ICME), IEEE, 2020: 1-6. [10] LI CH Y, GUO CH L, CHEN CH L. Learning to enhance low-light image via zero-reference deep curve estimation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 40(8): 4225-4238. [11] JIANG Y F, GONG X Y, LIU D, et al. EnlightenGAN: deep light enhancement without paired supervision[J]. IEEE Transactions on Image Processing, 2021, 30: 2340-2349. doi: 10.1109/TIP.2021.3051462 [12] FU Y, HONG Y, CHEN L W, et al. LE-GAN: Unsupervised low-light image enhancement network using attention module and identity invariant loss[J]. Knowledge-Based Systems, 2022, 240: 108010. doi: 10.1016/j.knosys.2021.108010 [13] WANG R J, JIANG B, YANG CH, et al. MAGAN: Unsupervised low-light image enhancement guided by mixed-attention[J]. Big Data Mining and Analytics, 2022, 5(2): 110-119. doi: 10.26599/BDMA.2021.9020020 [14] MONAKHOVA K, RICHTER S R, WALLER L, et al. Dancing under the stars: video denoising in starlight[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2022: 16220-16230. [15] CHEN J R, KAO S H, HE H, et al. Run, Don't walk: chasing higher FLOPS for faster neural networks[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2023: 12021-12031. [16] WEI CH, WANG W J, YANG W H, et al. Deep retinex decomposition for low-light enhancement[C]. British Machine Vision Conference 2018, BMVA Press, 2018: 155. [17] ZHANG Y, DI X G, ZHANG B, et al. Self-supervised low light image enhancement and denoising[J]. arXiv preprint arXiv: 2103.00832, 2021. [18] ZHANG Q L, YANG Y B. SA-Net: Shuffle attention for deep convolutional neural networks[C]. 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2021: 2235-2239. [19] XU X ZH, JIANG Y Q, CHEN W H, et al. DAMO-YOLO: a report on real-time object detection design[J]. arXiv preprint arXiv: 2211.15444, 2022. [20] TONG Z J, CHEN Y H, XU Z W, et al. Wise-IoU: Bounding box regression loss with dynamic focusing mechanism[J]. arXiv preprint arXiv: 2301.10051, 2023. [21] WU W H, WENG J, ZHANG P P, et al. URetinex-Net: Retinex-based deep unfolding network for low-light image enhancement[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2022: 5891-5900. [22] ZHANG F, LI Y, YOU SH D, et al. Learning temporal consistency for low light video enhancement from single images[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2021: 4965-4974. [23] MA L, MA T Y, LIU R SH, et al. Toward fast, flexible, and robust low-light image enhancement[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2022: 5627-5636. [24] LV F F, LU F, WU J H, et al. MBLLEN: Low-light image/video enhancement using CNNs[C]. British Machine Vision Conference 2018, BMVA Press, 2018: 220. -

 下载:
下载:




计量
- 文章访问数: 528
- HTML全文浏览量: 252
- PDF下载量: 170
- 被引次数: 0
