


Technology of virtual eyeglasses try-on system based on face pose estimation
-
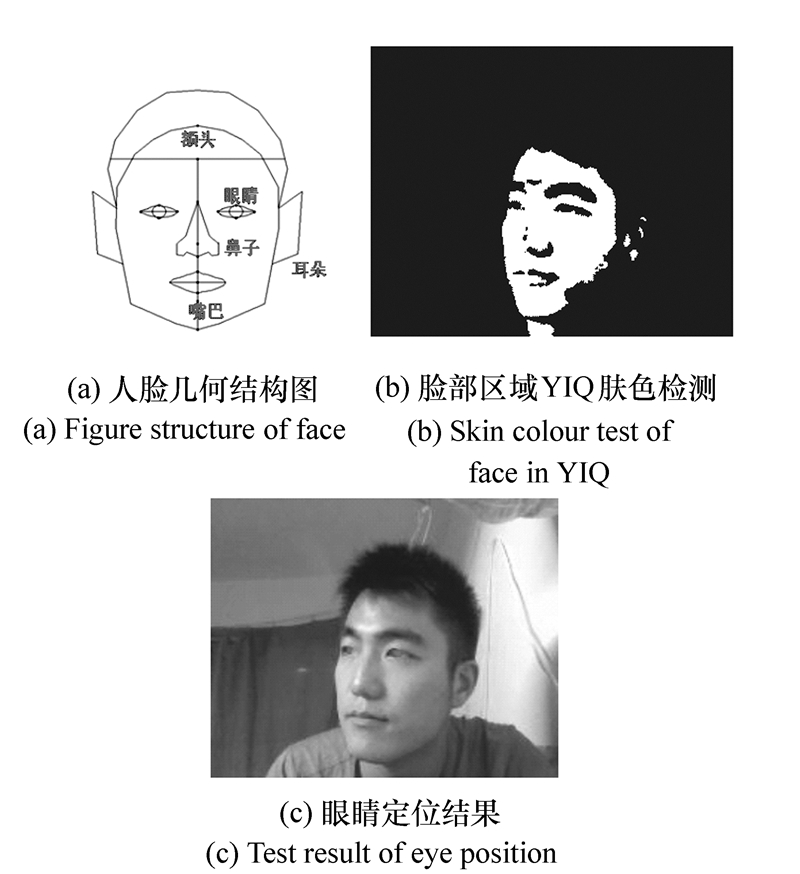
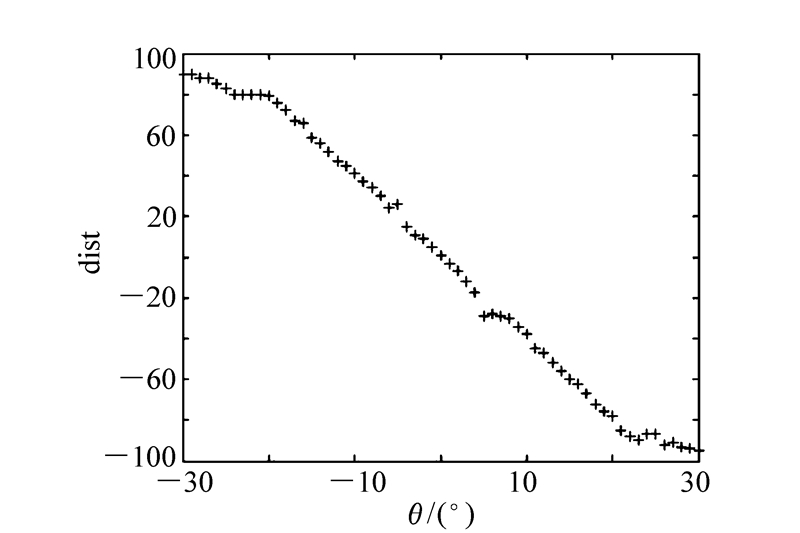
摘要: 为解决用户线上眼镜的最优选购,提出了一种基于人脸姿态估计的虚拟眼镜试戴技术。首先采用肤色模型与形状模型结合的算法对场景中的人脸区域进行检测,然后根据人眼在人脸中的几何位置关系实现人眼的精确定位;进一步利用人眼对称性先验知识来估计脸在三维空间中的姿态信息,即人脸与正面的偏移角度;最后,依据人眼位置和人脸姿态将眼镜图像融合到眼睛区域,即完成眼镜的虚拟试戴。该方法为3D环境下客户与商品之间虚拟视觉化的实现提供了一种可靠的技术支撑和应用思路。Abstract: In this paper, we present a new virtual eyeglasses try-on system based on face pose estimation, and provides technical support for the realization of the user online optimal commodity purchase. Firstly, we use color model combining shape model for face detection in the scene. Then, we use face geometry relationship to achieve precise positioning of the human eye. We furtherly estimate the face pose information based on a priori knowledge of the symmetrical of eyes in the face region, which is the deviation angle of face with the front side. Finally, we integrate the images of glasses to face and achieve the virtual eyeglasses try-on system according to calculating the angle and location information of eyes. This method provides a reliable technical support and application for the future implementation of virtual visualization between customers and goods in 3D environment.
-
Key words:
- pose estimation /
- image fusion /
- face detection /
- eye location
-
[1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] -

 下载:
下载:







图(8)
计量
- 文章访问数: 2414
- HTML全文浏览量: 715
- PDF下载量: 920
- 被引次数: 0
