


-
摘要: Canny算法在PC机上的执行速度较慢,这极大地限制了其实用性。本文在前人的研究基础上对算法进行更深的优化和改进。首先在VS2012开发环境下利用数字图像处理技术对原算法进行原理上的改进,再利用GPU流处理器数量众多的优势以及强大的多线程并发执行能力对Canny算法进行并行加速。在500 pixel×500 pixel的图片上,对本文算法和原Canny算法进行了实验验证。实验结果表明,在4 096 pixel×4 096 pixel大小的图片上采用本文的GPU移植算法处理后,执行速度从80 ms降到了6 ms以内。在不影响边缘检测效果的前提下极大地提高了算法的实用性。Abstract: Due to the slow execution speed of Canny algorithm in PC, the practicality of this algorithm is greatly restricted. Based on the previous studies, we further optimizes and improves the algorithm. First of all, we use the digital image processing technology to improve the original algorithm under the development environment of VS2012, and then accelerate the Canny algorithm by taking advantage of the large number of GPU stream processors and powerful multithreaded concurrent execution capability. Experiments were made on the improved algorithm and the original Canny algorithm. Experimental results show that in the 4 096×4 096 pixel-size images, the GPU migration algorithm presented in this paper can reduce the execution speed from 80 ms to less than 6 ms. Through this improvement, it can greatly improve the practicability of the algorithm without affecting the edge detection effect.
-
Key words:
- edge detection /
- GPU /
- parallel processing /
- connected component extraction
-

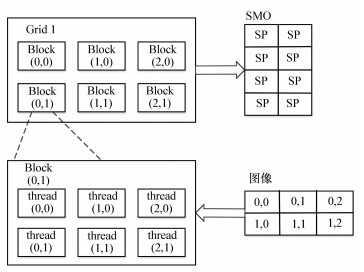
图 4 搜索方法优化示意图 4(a)(左), 4(b)(右)
Figure 4. Schematic diagram of optimizing search and connection, 4(a)(left)) and 4(b)(right)

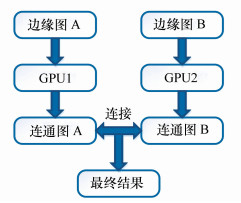
图 6 不同算法的比较结果(左图CPU, 右图GPU)
Figure 6. Comparison of two results by CPU(left) and GPU(right)

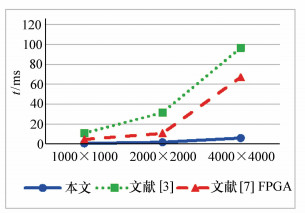
图 7 本文算法、OpenCV库及GPU库算法的结果比较
Figure 7. Results comparison of proposed method, OpenCV-lib and GPU-lib methods

表 1 C语言实现Canny算法各步骤执行时间
Table 1. Execution time of each step for Canny algorithm in C language
(ms) 高斯滤波 非极大值抑制 边缘搜索 总计 4 096×4 096 57.4 5 17.6 82  下载: 导出CSV
下载: 导出CSV
表 2 对于4 096×4 096大小的图片双GPU优化本文改进算法执行时间
Table 2. Execution time by proposed method based on dual-GPU optimization on image with size of 4 096×4 096
(ms) 高斯滤波 非极大值抑制 边缘搜索 总计 单980 1.52 2.15 2.3 5.9 双980 0.7 1.1 1.5 3.3
下载: 导出CSV
-
[1] CANNY J. A computational approach to edge detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1986, 6:679-698. http://dl.acm.org/citation.cfm?id=11274.11275 [2] 丁鹏, 张叶, 刘让, 等.结合形态学和Canny算法的红外弱小目标检测[J].液晶与显示, 2016, 31(8):793-800. http://kns.cnki.net/KCMS/detail/detail.aspx?filename=yjys201608010&dbname=CJFD&dbcode=CJFQDING P, ZHANG Y, LIU R, et al.. Infrared small target detection based on adaptive Canny algorithm and morphology[J]. Chinese Journal of Liquid Crystals and Displays, 2016, 31(8):793-800.(in Chinese) http://kns.cnki.net/KCMS/detail/detail.aspx?filename=yjys201608010&dbname=CJFD&dbcode=CJFQ [3] 朱玉娥, 吴晓红, 何小海.基于GPU图像边缘检测的实时性[J].电子测量技术, 2009, 32(2):140-142. http://kns.cnki.net/KCMS/detail/detail.aspx?filename=dzcl200902040&dbname=CJFD&dbcode=CJFQZHU Y E, WU X H, HE X H. Real-time edge detection based on GPU[J]. Electronic Measurement Technology, 2009, 32(2):140-142.(in Chinese) http://kns.cnki.net/KCMS/detail/detail.aspx?filename=dzcl200902040&dbname=CJFD&dbcode=CJFQ [4] 唐斌, 龙文.基于GPU+CPU的CANNY算子快速实现[J].液晶与显示, 2016, 31(7):714-720. http://cjl.opticsjournal.net/Articles/Abstract?aid=OJ160829000307VsYu2xTANG B, LONG W. Fast Canny algorithm based on GPU+CPU[J]. Chinese Journal of Liquid Crystals and Displays, 2016, 31(7):714-720.(in Chinese) http://cjl.opticsjournal.net/Articles/Abstract?aid=OJ160829000307VsYu2x [5] 李大禹.基于多GPU的液晶自适应光学波前处理器[J].液晶与显示, 2016, 31(5):491-496. http://kns.cnki.net/KCMS/detail/detail.aspx?filename=yjys201605011&dbname=CJFD&dbcode=CJFQLI D Y. Liquid crystal adaptive optics wavefront processor based on multi-GPU[J]. Chinese Journal of Liquid Crystals and Displays, 2016, 31(5):491-496.(in Chinese) http://kns.cnki.net/KCMS/detail/detail.aspx?filename=yjys201605011&dbname=CJFD&dbcode=CJFQ [6] 张宏薇, 王仕洋, 李宪龙, 等.基于Hough变换的瞳孔识别方法研究与实现[J].液晶与显示, 2016, 31(6):621-625. http://kns.cnki.net/KCMS/detail/detail.aspx?filename=yjys201606014&dbname=CJFD&dbcode=CJFQZHANG H W, WANG SH Y, LI X L, et al.. Research and implementation of pupil recognition based on Hough transform[J]. Chinese Journal of Liquid Crystals and Displays, 2016, 31(6):621-625.(in Chinese) http://kns.cnki.net/KCMS/detail/detail.aspx?filename=yjys201606014&dbname=CJFD&dbcode=CJFQ [7] 张素文, 陈志星, 苏义鑫.Canny边缘检测算法的改进及FPGA实现[J].红外技术, 2010, 32(2):93-96. http://kns.cnki.net/KCMS/detail/detail.aspx?filename=kbck201003024&dbname=CJFD&dbcode=CJFQZHANG S W, CHEN ZH X, SU Y X. Improved Canny edge detection algorithm and implementation in FPGA[J]. Infrared Technology, 2010, 32(2):93-96.(in Chinese) http://kns.cnki.net/KCMS/detail/detail.aspx?filename=kbck201003024&dbname=CJFD&dbcode=CJFQ [8] Canny edge detection algorithm principle and its VC implement[EB/OL].http://blog.csdn.net/augusdi/article/details/12907151. [9] 周海芳. 遥感图像并行处理算法的研究与应用[D]. 长沙: 国防科学技术大学, 2003. http://cdmd.cnki.com.cn/Article/CDMD-90002-2005014480.htmZHOU H F. Research and application of parallel acceleration in remote sensing image[D]. Changsha:National University of Defense Technology, 2003.(in Chinese) http://cdmd.cnki.com.cn/Article/CDMD-90002-2005014480.htm [10] 徐亮, 魏锐.基于Canny算子的图像边缘检测优化算法[J].科技通报, 2013, 29(7):127-131. http://kns.cnki.net/KCMS/detail/detail.aspx?filename=kjtb201307025&dbname=CJFD&dbcode=CJFQXU L, WEI R. An optimal algorithm of image edge detection based on Canny[J]. Bulletin of Science and Technology, 2013, 29(7):127-131.(in Chinese) http://kns.cnki.net/KCMS/detail/detail.aspx?filename=kjtb201307025&dbname=CJFD&dbcode=CJFQ [11] 曾文静, 万磊, 张铁栋, 等.复杂海空背景下弱小目标的快速自动检测[J].光学 精密工程, 2012, 20(2):403-412. http://kns.cnki.net/KCMS/detail/detail.aspx?filename=gxjm201202026&dbname=CJFD&dbcode=CJFQZENG W J, WAN L, ZHANG T D, et al.. Fast detection of weak targets in complex sea-sky background[J]. Opt. Precision Eng., 2012, 20(2):403-412.(in Chinese) http://kns.cnki.net/KCMS/detail/detail.aspx?filename=gxjm201202026&dbname=CJFD&dbcode=CJFQ [12] 陈娟, 陈乾辉, 师路欢, 等.图像跟踪中的边缘检测技术[J].中国光学, 2009, 2(1):46-53. http://www.chineseoptics.net.cn/CN/abstract/abstract8371.shtmlCHEN J, CHEN Q H, SHI L H, et al.. Edge detection technology in imaging tracking[J]. Chinese Optics, 2009, 2(1):46-53.(in Chinese) http://www.chineseoptics.net.cn/CN/abstract/abstract8371.shtml [13] XU Q, VARADARAJAN S, CHAKRABARTI C, et al. A distributed canny edge detector:algorithm and FPGA implementation[J]. IEEE Transactions on Image Processing, 2014, 23(7):2944-2960. doi: 10.1109/TIP.2014.2311656 [14] 周克良, 周利锋, 刘太钢, 等.基于改进的Canny算子实时视频边缘检测系统在FPGA上的设计与实现[J].计算机测量与控制, 2016, 24(1):219-222. http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jzck201601062&dbname=CJFD&dbcode=CJFQZHOU K L, ZHOU L F, LIU T G, et al.. Design and implementation of real-time video edge detection system based on improvement of canny algorithm on FPGA[J]. Computer Measurement & Control, 2016, 24(1):219-222.(in Chinese) http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jzck201601062&dbname=CJFD&dbcode=CJFQ [15] 王希远, 成荣, 朱煜, 等.基于FPGA的BiSS-C协议编码器接口技术研究及解码实现[J].液晶与显示, 2016, 31(4):386-391. http://kns.cnki.net/KCMS/detail/detail.aspx?filename=yjys201604009&dbname=CJFD&dbcode=CJFQWANG X Y, CHENG R, ZHU Y, et al.. Research and realization of BiSS-C protocol encoder interface based on FPGA[J]. Chinese Journal of Liquid Crystals and Displays, 2016, 31(4):386-391.(in Chinese) http://kns.cnki.net/KCMS/detail/detail.aspx?filename=yjys201604009&dbname=CJFD&dbcode=CJFQ -

 下载:
下载:






计量
- 文章访问数: 2189
- HTML全文浏览量: 767
- PDF下载量: 677
- 被引次数: 0
