


-
摘要:
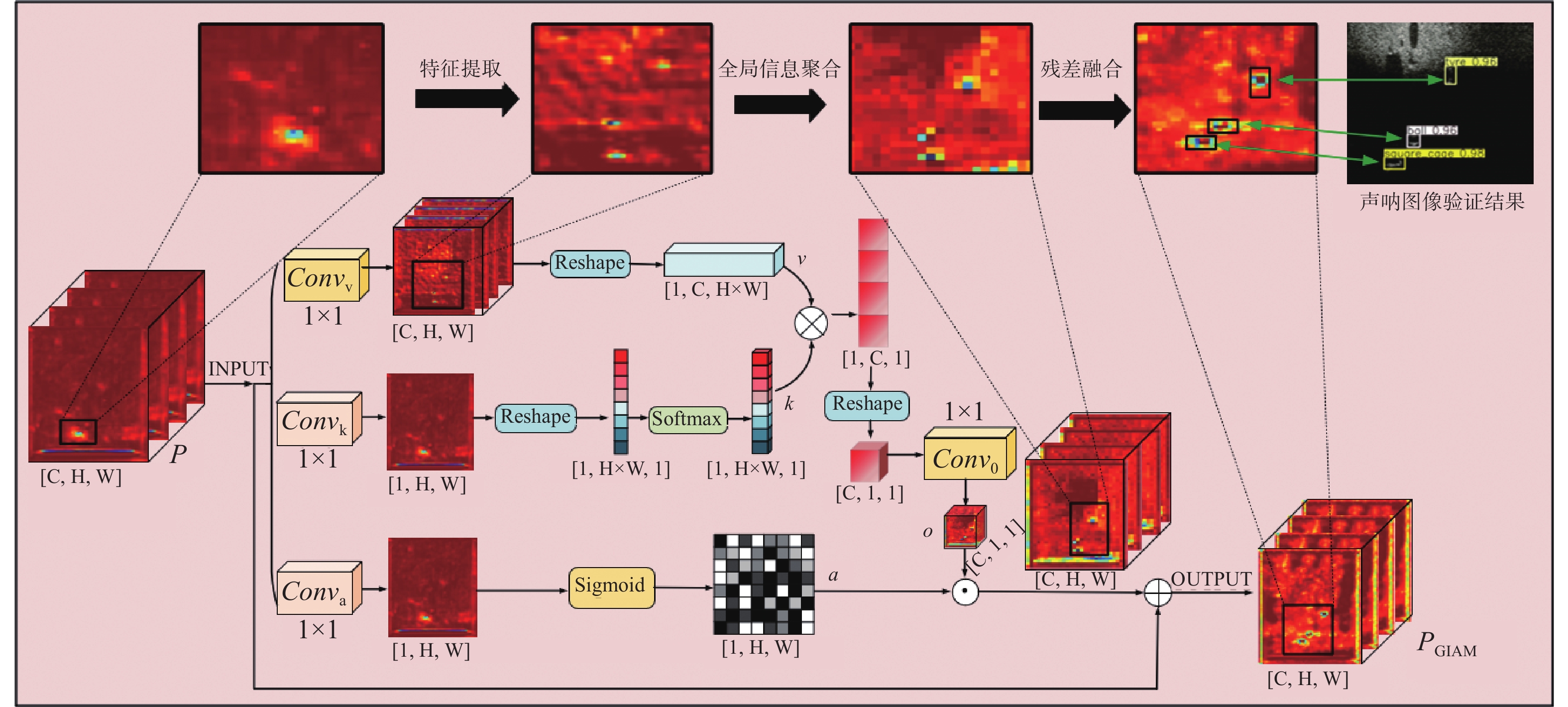
声呐图像视觉检测是复杂水域资源勘探和水下异物目标探测领域的重要技术之一。针对声呐图像中小目标存在的特征微弱和背景信息干扰问题,本文提出弱特征共焦通道调控水下声呐目标检测算法。为了提高模型对弱小目标的信息捕获和表征能力,设计弱小目标特征激活策略,并引入先验框尺度校准机制匹配底层语义特征检测分支,以提高小目标检测精度。应用全局信息聚合模块深入挖掘弱小目标的全局特征,避免冗余信息覆盖小目标微弱关键特征。为解决传统空间金字塔池化易忽视通道信息的问题,提出共焦通道调控池化模块,保留有效通道域小目标信息并克服复杂背景信息干扰。实验结果表明,本文所提模型在水下声呐数据集的9类弱小目标识别的平均检测精度达83.3%,相较基准提高了5.5%,其中铁桶、人体模型和立方体检测精度得到显著提高,分别提高24%、8.6%和7.3%,有效改善水下复杂环境中弱小目标漏检和误检问题。
Abstract:Visual detection of sonar images is a critical technology in complex water resource exploration and underwater foreign object target detection. Aiming at the problems of weak features and background information interference of small targets in sonar images, we propose a weak feature confocal channel modulation algorithm for underwater sonar target detection. First, in order to improve the model's ability to capture and characterize the information of weak targets, we design a weak target-specific activation strategy and introduce an a priori frame scale calibration mechanism to match the underlying semantic feature detection branch to improve the accuracy of small target detection; second, we apply the global information aggregation module to deeply excavate the global features of weak targets to avoid the redundant information from covering the small target's weak key features; finally, in order to solve the problem of traditional spatial pyramid pooling which is easy to ignore the channel information, the confocal channel regulation pooling module is proposed to retain effective channel domain small target information and overcome interference from complex background information. Experiment results show that the model in this paper achieves an average detection accuracy of 83.3% on nine types of weak targets in the underwater sonar dataset, which is 5.5% higher than the benchmark. Among these, the detection accuracy of iron buckets, human body models and cubes is significantly improved by 24%, 8.6%, and 7.3%, respectively, effectively solving the problem of leakage and misdetection of weak targets in complex underwater environment.
-
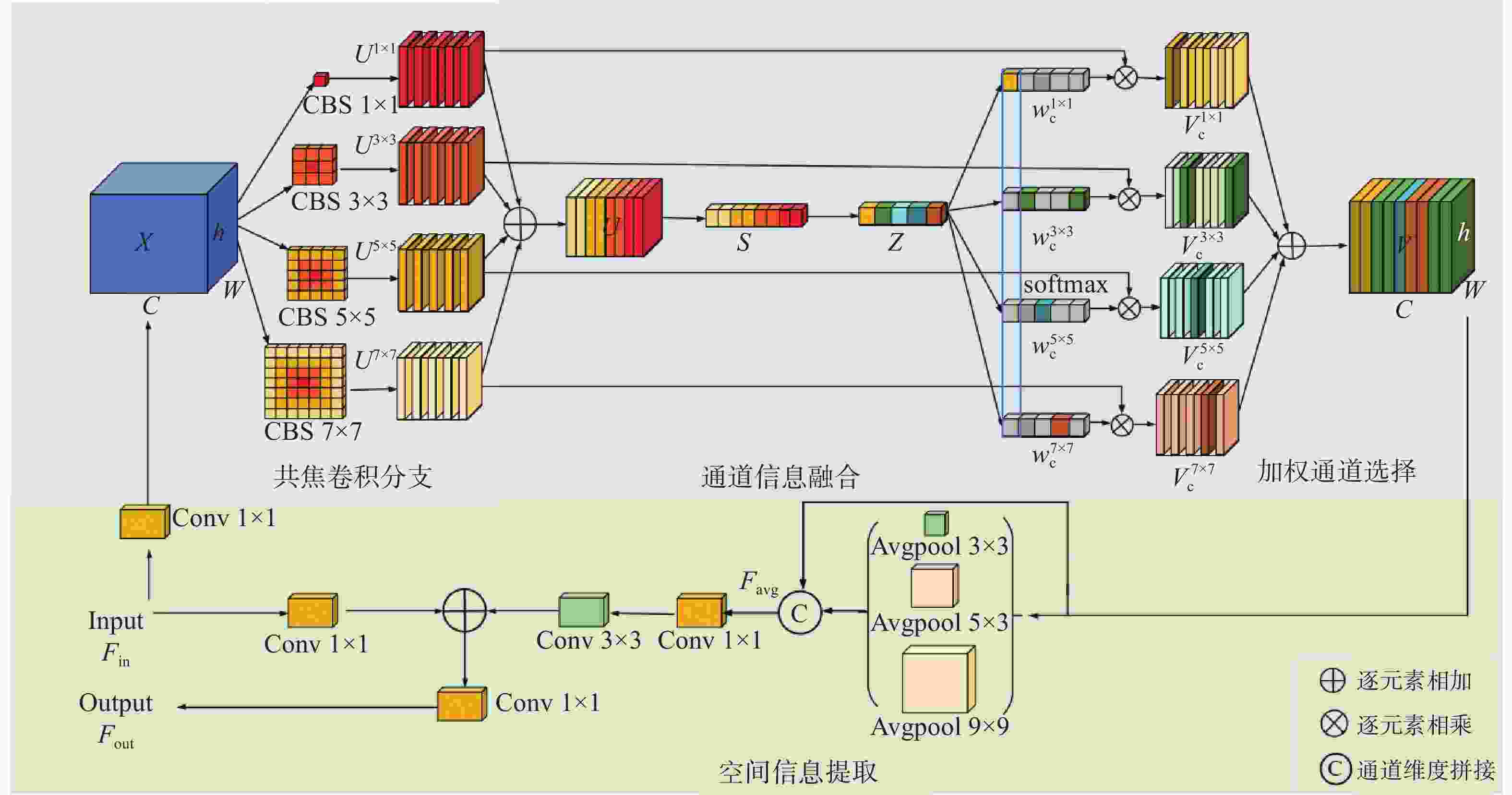
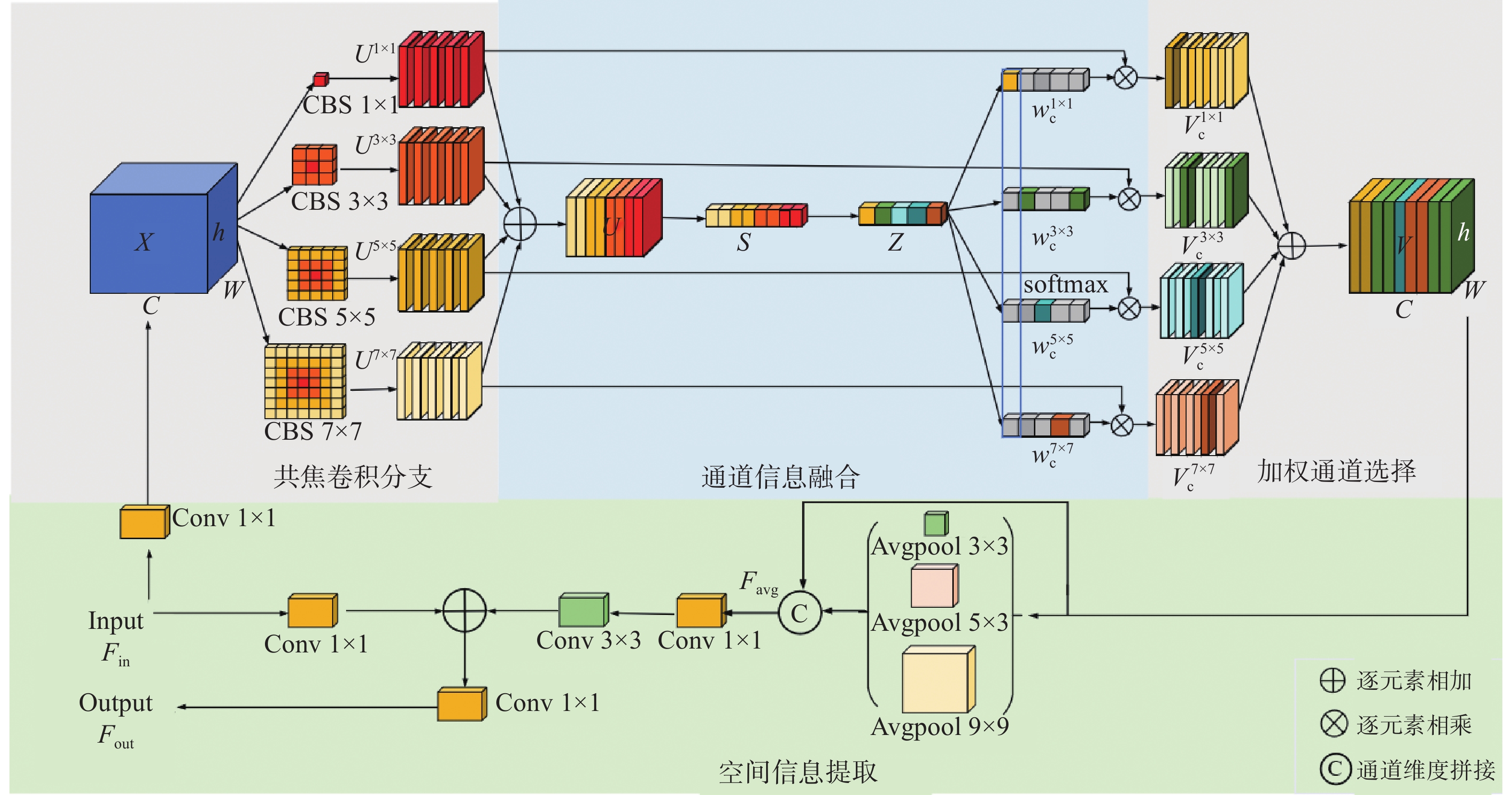
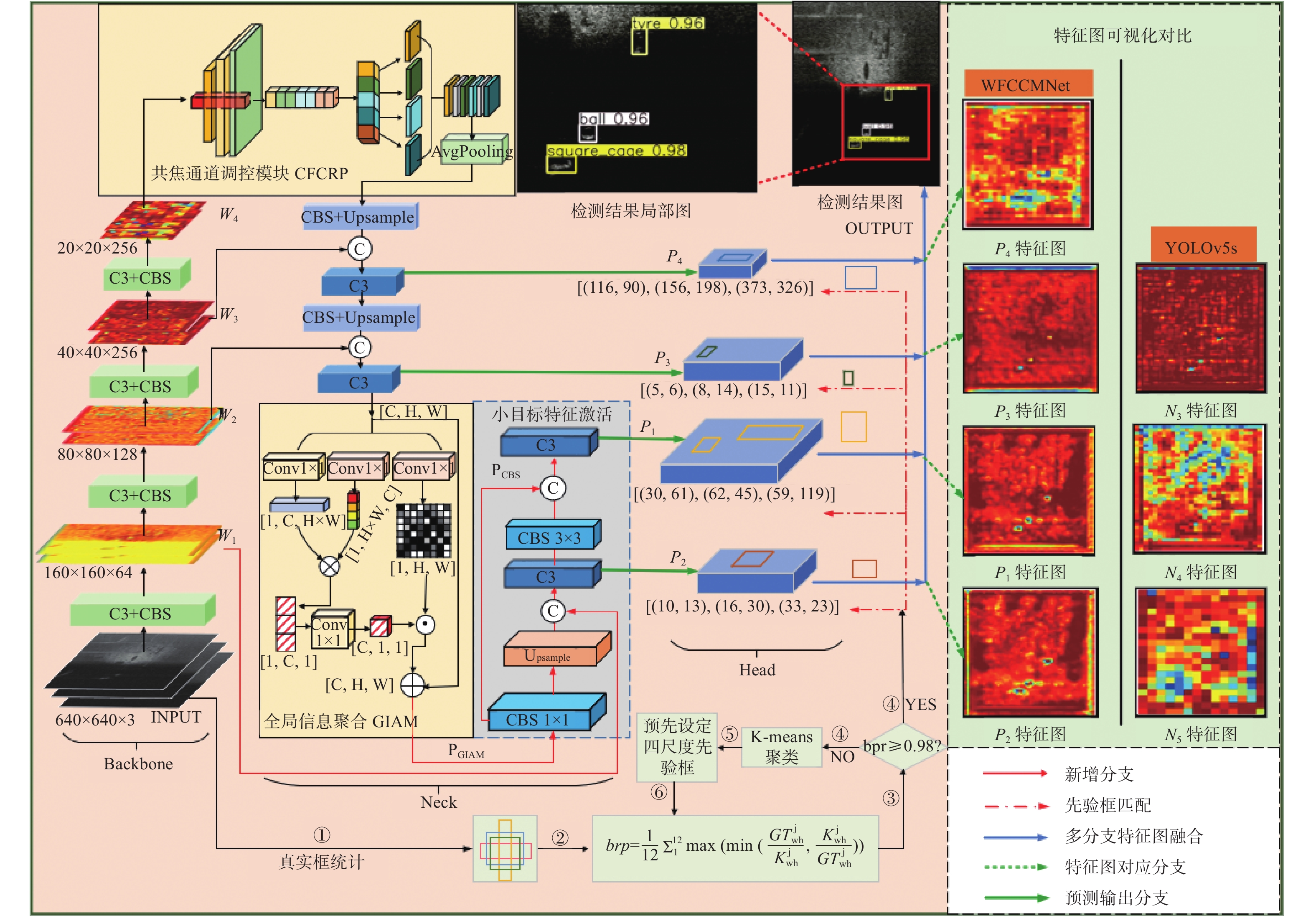
图 3 共焦通道调控池化模块结构图
Figure 3. Structural diagram of confocal channel regulation pooling module
表 1 改进前后输出分支与先验框对应关系
Table 1. Correspondence between output branches and a priori boxes before and after improvement
改进前 改进后 输出
分支先验框
尺度输出
分支先验框
尺度- - P4 [(116,90),(156,198),(373,326)] N3 [(10,13),(16,30),(33,23)] P3 [(5,6),(8,14),(15,11)] N4 [(30,61),(62,45),(59,119)] P2 [(10,13),(16,30),(33,23)] N5 [(116,90),(156,198),(373,326)] P1 [(30,61),(62,45),(59,119)]  下载: 导出CSV
下载: 导出CSV
表 2 目标图像面积占比
Table 2. Target image area percentage
Classes name Maximum area of target frame(height×width) Ration ball 156×142 0.04 circle cage 128×148 0.04 cube 140×164 0.04 cylinder 122×102 0.02 human body 215×216 0.09 metal bucket 168×206 0.07 plane 187×278 0.10 square cage 130×118 0.03 tyre 166×166 0.05
下载: 导出CSV
表 3 改进模块消融实验
Table 3. Improved module ablation experiments
GFLOPS mAP50 human body ball circle cage square cage tyre metal bucket cube cylinder plane Baseline 15.8 77.8 81.2 84.9 81.6 78.7 64.8 61.1 84.4 71.8 92.5 +特征激活 18.6 80.1 87.6 82.5 81.1 80.9 64.9 68.8 86.4 77.5 91 +GIAM 19.5 80.9 86.8 83.8 84.1 78.5 64.3 80.1 85.8 74.8 90.3 +CFCRP 23.7 83.3 89.8 85.7 79.1 82.9 73.1 85.1 91.7 71.2 91
下载: 导出CSV
表 4 实验代号与输出分支和先验框尺度对应关系
Table 4. Correspondence of experiment codes with output layers and a priori boxes
实验代号 输出分支 先验框尺度 输出分支 先验框尺度 G1 - - N4 [(30,61),(62,45),(59,119)] N3 [(10,13),(16,30),(33,23)] N5 [(116,90),(156,198),(373,326)] G2 P4 [(5,6),(8,14),(15,11)] P2 [(30,61),(62,45),(59,119)] P3 [(10,13),(16,30),(33,23)] P1 [(116,90),(156,198),(373,326)] G3 P4 [(10,13),(16,30),(33,23)] P2 [(30,61),(62,45),(59,119)] P3 [(5,6),(8,14),(15,11)] P1 [(116,90),(156,198),(373,326)] G4 P4 [(30,61),(62,45),(59,119)] P2 [(10,13),(16,30),(33,23)] P3 [(5,6),(8,14),(15,11)] P1 [(116,90),(156,198),(373,326)] G5 P4 [(116,90),(156,198),(373,326)] P2 [(10,13),(16,30),(33,23)] P3 [(5,6),(8,14),(15,11)] P1 [(30,61),(62,45),(59,119)]
下载: 导出CSV
表 5 检测分支与先验框组合定量实验结果
Table 5. Results of quantitative experiments on the combination of detection branch and a priori frame
实验代号 GFLOPS mAP50 human body ball circle cage square cage tyre metal bucket cube cylinder plane G1 15.8 77.8 81.2 84.9 81.6 78.7 64.8 61.1 84.4 71.8 92.5 G2 15.9 78.6 88.8 83.7 79.7 82.6 60.6 66.9 87.1 68.5 89.7 G3 15.9 77.5 77.9 82.3 80.7 72.4 63.9 67.6 86.9 73.7 92.1 G4 15.9 79.2 79.9 81.7 78.5 75.2 64.4 74.2 87.3 76.6 95.1 G5 15.9 79.3 89.4 83.2 78.6 83.3 63 71.1 84.3 71.2 90
下载: 导出CSV
表 6 多尺度共焦卷积对比实验
Table 6. Multi-scale confocal convolution comparison experiments
Base Model 共焦卷积核 GFLOPS mAP50 human body ball circle cage square cage tyre metal bucket cube cylinder plane YOLOv5s
+特征激活
+GIAM- 19.5 80.9 86.8 83.8 84.1 78.5 64.3 80.1 85.8 74.8 90.3 +1×1 19.3 80.8 85.3 86.1 67.3 85.1 71.3 84.5 89.7 68.8 89.5 +1×1
+3×319.4 81.4 89.4 84.1 78.8 83.3 66.1 87.5 87.1 68.7 87.5 +1×1
+3×3
+5×520.8 80.6 91.8 83.4 75 79.1 67.2 72.3 87.2 80.5 88.8 +1×1
+3×3
+5×5
+7×723.7 83.3 89.8 85.7 79.1 82.9 73.1 85.1 91.7 71.2 91 +1×1
+3×3
+5×5
+7×7
+9×927.6 78.2 85.3 84.9 74 80.2 66.4 78.2 88.6 61.6 84.6
下载: 导出CSV
表 7 空间特征金字塔池化对比实验
Table 7. Spatial feature pyramid pooling comparison experiments
Base Model 空间特征金字塔池化 GFLOPS mAP50 human body ball circle cage square cage tyre metal bucket cube cylinder plane YOLOv5s
+特征激活
+GIAM+SPPF 19.5 80.9 86.8 83.8 84.1 78.5 64.3 80.1 85.8 74.8 90.3 +SPP 18.5 81.4 86.1 83.6 81.9 86.8 67.5 73.2 86.4 76.8 90.2 +SPPFCSPC 23.6 73.9 78.1 79.7 71.6 76.5 60.3 60.4 85.4 62.1 91.2 +ASPP 25.1 77 78.4 80.1 72.8 77.6 70 76.6 88 61.8 87.9 +RFB 19.0 80.5 86.8 85.8 78.7 80.4 69.7 80.3 87.2 72.2 83.8 +SPPCSPC 23.6 75.2 80.3 78.6 73.4 72.8 62.4 71.4 82.4 72.3 83.1 +CFCRP 23.7 83.3 89.8 85.7 79.1 82.9 73.1 85.1 91.7 71.2 91
下载: 导出CSV
表 8 网络模型对比实验
Table 8. Network model comparison experiment
Model GFLOPS mAP50 human body ball circle cage square cage tyre metal bucket cube cylinder plane SSD[38] 347.1 78.8 89.1 90.9 74.8 76.4 62.3 77.4 81 68.4 89 RetinaNet[39] 207.9 68.4 89.8 77.5 59.8 74.7 47.4 75.9 78.6 24 87.9 YOLOv5x[40] 203.9 77.4 76.1 83.8 76.8 72.7 62.3 80 83.8 66.2 95 Faster RCNN[41] 193.8 71.2 80.4 81.1 77.6 75.7 45 70 81.8 40.4 88.7 YOLOv7[29] 103.3 60.4 71.5 74.2 57.8 67 48.1 59.8 72.8 35.8 56.4 YOLOv5m[40] 48 71.3 68.6 81.8 79 61.5 56.7 58.9 85.1 69.3 80.7 DAMO-YOLO[42] 36 72.7 65.5 81.3 70.2 70.8 38.7 87.8 85.6 71.8 82.2 YOLOv8s[43] 28.2 81.4 82.3 86.5 81.1 86.6 65 93.7 88.5 53.5 95 YOLOXs[44] 26.7 82.4 88.1 88 75.9 87.2 71.7 79.3 89.6 71.4 90 YOLOv5s[40] 15.8 77.8 81.2 84.9 81.6 78.7 64.8 61.1 84.4 71.8 92.5 YOLOv7-tiny[45] 13.1 64.2 70.3 84.5 46.7 76.8 35.4 66.3 83.3 41.7 72.7 YOLOv3-tiny[41] 5.57 63.2 65.2 73.6 69.4 63.2 37.5 63.9 76 48 72.1 YOLOv5n[40] 4.2 72.3 86 79.2 74.5 77.9 59.3 52.8 81.8 58 80.8 WFCCMNet 23.7 83.3 89.8 85.7 79.1 82.9 73.1 85.1 91.7 71.2 91
下载: 导出CSV
-
[1] 王芳. 新时期海洋强国建设形势与任务研究[J]. 中国海洋大学学报(社会科学版),2020(5):11-19.WANG F. Research on the situation and tasks of building a strong maritime power in the new era[J]. Journal of Ocean University of China (Social Sciences), 2020(5): 11-19. (in Chinese). [2] CLAY C S, HORNE J K. Acoustic models of fish: the Atlantic cod (Gadus morhua)[J]. The Journal of the Acoustical Society of America, 1994, 96(3): 1661-1668. doi: 10.1121/1.410245 [3] HARLEY H E, DELONG C M. Echoic object recognition by the bottlenose dolphin[J]. Comparative Cognition & Behavior Reviews, 2008, 3: 46-65. [4] 谭亦秋. 基于直流超导量子干涉仪的水下铁磁性目标探测技术研究[D]. 长沙: 国防科技大学, 2020.TAN Y Q. Research on detection technology of underwater ferromagnetic target based on DC superconducting quantum interference device[D]. Changsha: National University of Defense Technology, 2020. (in Chinese). [5] 陈正想, 卢俊杰. 弱磁探测技术发展现状[J]. 水雷战与舰船防护,2011,19(4):1-5,24.CHEN ZH X, LU J J. Current development of weak magnetic detection[J]. Mine Warfare & Ship Self-Defence, 2011, 19(4): 1-5,24. (in Chinese). [6] XU W H, YANG J M, WEI H D, et al. A localization algorithm based on pose graph using Forward-looking sonar for deep-sea mining vehicle[J]. Ocean Engineering, 2023, 284: 114968. doi: 10.1016/j.oceaneng.2023.114968 [7] 罗逸豪. 基于深度学习的声呐图像目标检测系统[J]. 数字海洋与水下攻防,2023,6(4):423-428.LUO Y H. Sonar image object detection system based on deep learning[J]. Digital Ocean & Underwater Warfare, 2023, 6(4): 423-428. (in Chinese). [8] ISHAK A B. A two-dimensional multilevel thresholding method for image segmentation[J]. Applied Soft Computing, 2017, 52: 306-322. doi: 10.1016/j.asoc.2016.10.034 [9] ZHANG B M, ZHOU T, SHI ZI F, et al. An underwater small target boundary segmentation method in forward-looking sonar images[J]. Applied Acoustics, 2023, 207: 109341. doi: 10.1016/j.apacoust.2023.109341 [10] 万广南. 基于激光和超声的水下目标探测方法研究[D]. 哈尔滨: 哈尔滨工业大学, 2017.WAN G N. Research on underwater target detection based laser and ultrasound[D]. Harbin: Harbin Institute of Technology, 2017. (in Chinese). [11] 翟厚曦, 江泽林, 张鹏飞, 等. 一种合成孔径声呐图像目标分割方法[J]. 仪器仪表学报,2016,37(4):887-894. doi: 10.3969/j.issn.0254-3087.2016.04.022ZHAI H X, JIANG Z L, ZHANG P F, et al. Object segmentation method for synthetic aperture sonar images[J]. Chinese Journal of Scientific Instrument, 2016, 37(4): 887-894. (in Chinese). doi: 10.3969/j.issn.0254-3087.2016.04.022 [12] 杨卫东, 叶长彬, 陈正林, 等. 基于snake算法的声呐图像轮廓提取方法[J]. 压电与声光,2023,45(5):752-758.YANG W D, YE CH B, CHEN ZH L, et al. Image contour extraction method based on snake algorithm[J]. Piezoelectrics & Acoustooptics, 2023, 45(5): 752-758. (in Chinese). [13] 胡钢. 基于深度学习的水下目标识别和运动行为分析技术研究[D]. 哈尔滨: 哈尔滨工程大学, 2021.HU G. Research on underwater target recognition and motion behavior analysis technology based on deep learning[D]. Harbin: Harbin Engineering University, 2021. (in Chinese). [14] DIVYABARATHI G, SHAILESH S, JUDY M V. Object classification in underwater SONAR images using transfer learning based ensemble model[C]. Proceedings of 2021 International Conference on Advances in Computing and Communications, IEEE, 2021: 1-4. [15] CHANDRASHEKAR G, RAAZA A, RAJENDRAN V, et al. Side scan sonar image augmentation for sediment classification using deep learning based transfer learning approach[J]. Materials Today: Proceedings, 2023, 80: 3263-3273. doi: 10.1016/j.matpr.2021.07.222 [16] KONG W Z, HONG J CH, JIA M Y, et al. YOLOv3-DPFIN: a dual-path feature fusion neural network for robust real-time sonar target detection[J]. IEEE Sensors Journal, 2020, 20(7): 3745-3756. doi: 10.1109/JSEN.2019.2960796 [17] ZHAO L, LI S. Object detection algorithm based on improved YOLOv3[J]. Electronics, 2020, 9(3): 537. [18] FAN X N, LU L, SHI P F, et al. A novel sonar target detection and classification algorithm[J]. Multimedia Tools and Applications, 2022, 81(7): 10091-10106. doi: 10.1007/s11042-022-12054-4 [19] WANG C Y, Bochkovskiy A, Liao H Y M. Scaled-yolov4: Scaling cross stage partial network[C]//Proceedings of the IEEE/cvf conference on computer vision and pattern recognition. 2021: 13029-13038. [20] GERG I D, MONGA V. Structural prior driven regularized deep learning for sonar image classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 4200416. [21] NANDHINI S, ASHOKKUMAR K. An automatic plant leaf disease identification using DenseNet-121 architecture with a mutation-based henry gas solubility optimization algorithm[J]. Neural Computing and Applications, 2022, 34(7): 5513-5534. doi: 10.1007/s00521-021-06714-z [22] ZHU X Y, LIANG Y SH, ZHANG J L, et al. STAFNet: swin transformer based anchor-free network for detection of forward-looking sonar imagery[C]. Proceedings of the 2022 International Conference on Multimedia Retrieval, ACM, 2022: 443-450. [23] LIU Z, LIN Y T, CAO Y, et al. Swin transformer: hierarchical vision transformer using shifted windows[C]. Proceedings of 2021 IEEE/CVF International Conference on Computer Vision, IEEE, 2021: 10012-10022. [24] 刘彦磊, 李孟喆, 王宣宣. 轻量型YOLOv5s车载红外图像目标检测[J]. 中国光学(中英文),2023,16(5):1045-1055. doi: 10.37188/CO.2022-0254LIU Y L, LI M ZH, WANG X X. Lightweight YOLOv5s vehicle infrared image target detection[J]. Chinese Optics, 2023, 16(5): 1045-1055. doi: 10.37188/CO.2022-0254 [25] 朱威, 王立凯, 靳作宝, 等. 引入注意力机制的轻量级小目标检测网络[J]. 光学 精密工程,2022,30(8):998-1010. doi: 10.37188/OPE.20223008.0998ZHU W, WANG L K, JIN Z B, et al. Lightweight small object detection network with attention mechanism[J]. Optics and Precision Engineering, 2022, 30(8): 998-1010. (in Chinese). doi: 10.37188/OPE.20223008.0998 [26] 乔美英, 史建柯, 李冰锋, 等. 改进损失函数的增强型FPN水下小目标检测[J]. 计算机辅助设计与图形学学报,2023,35(4):525-537.QIAO M Y, SHI J K, LI B F, et al. Enhanced FPN underwater small target detection with improved loss function[J]. Journal of Computer-Aided Design & Computer Graphics, 2023, 35(4): 525-537. (in Chinese). [27] 张艳, 李星汕, 孙叶美, 等. 基于通道注意力与特征融合的水下目标检测算法[J]. 西北工业大学学报,2022,40(2):433-441. doi: 10.3969/j.issn.1000-2758.2022.02.025ZHANG Y, LI X SH, SUN Y M, et al. Underwater object detection algorithm based on channel attention and feature fusion[J]. Journal of Northwestern Polytechnical University, 2022, 40(2): 433-441. (in Chinese). doi: 10.3969/j.issn.1000-2758.2022.02.025 [28] LI L, LI Y P, YUE CH H, et al. Real-time underwater target detection for AUV using side scan sonar images based on deep learning[J]. Applied Ocean Research, 2023, 138: 103630. doi: 10.1016/j.apor.2023.103630 [29] WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]. Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, IEEE, 2023: 7464-7475. [30] 张绍文, 史卫亚, 张世强, 等. 基于加权感受野和跨层融合的遥感小目标检测[J]. 电子测量技术,2023,46(18):129-138.ZHANG SH W, SHI W Y, ZHANG SH Q, et al. Remote sensing small target detection based on weighted receptive field and cross-layer fusion[J]. Electronic Measurement Technology, 2023, 46(18): 129-138. (in Chinese). [31] CUI L SH, LV P, JIANG X H, et al. Context-aware block net for small object detection[J]. IEEE Transactions on Cybernetics, 2022, 52(4): 2300-2313. doi: 10.1109/TCYB.2020.3004636 [32] Chen Y, Guo Q, Liang X, et al. Environmental sound classification with dilated convolutions[J]. Applied Acoustics, 2019, 148: 123-132. [33] WANG C Y, LIAO H Y M, WU Y H, et al. CSPNet: a new backbone that can enhance learning capability of CNN[C]. Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, IEEE, 2020: 390-391. [34] XIE K, YANG J, QIU K. A dataset with multibeam forward-looking sonar for underwater object detection[J]. Scientific Data, 2022, 9(1): 739. [35] 刘颖, 刘红燕, 范九伦, 等. 基于深度学习的小目标检测研究与应用综述[J]. 电子学报,2020,48(3):590-601. doi: 10.3969/j.issn.0372-2112.2020.03.024LIU Y, LIU H Y, FAN J L, et al. A survey of research and application of small object detection based on deep learning[J]. Acta Electronica Sinica, 2020, 48(3): 590-601. (in Chinese). doi: 10.3969/j.issn.0372-2112.2020.03.024 [36] CHEN CH Y, LIU M Y, TUZEL O, et al. R-CNN for small object detection[C]. Proceedings of the 13th Asian Conference on Computer Vision, Springer, 2017: 214-230. [37] 高新波, 莫梦竟成, 汪海涛, 等. 小目标检测研究进展[J]. 数据采集与处理,2021,36(3):391-417.GAO X B, MO M J CH, WANG H T, et al. Recent advances in small object detection[J]. Journal of Data Acquisition and Processing, 2021, 36(3): 391-417. (in Chinese). [38] LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector[C]. Proceedings of the 14th European Conference, Springer, 2016: 21-37. [39] WANG Y Y, WANG CH, ZHANG H, et al. Automatic ship detection based on RetinaNet using multi-resolution Gaofen-3 imagery[J]. Remote Sensing, 2019, 11(5): 531. doi: 10.3390/rs11050531 [40] WU W, LIU H, LI L, et al. Application of local fully convolutional neural network combined with YOLO v5 algorithm in small target detection of remote sensing image[J]. PloS one, 2021, 16(10): e0259283. [41] REN SH Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. doi: 10.1109/TPAMI.2016.2577031 [42] Dewi C, Chen A P S, Christanto H J. Recognizing similar musical instruments with YOLO models[J]. Big Data and Cognitive Computing, 2023, 7(2): 94. [43] HUSSAIN M. YOLO-v1 to YOLO-v8, the rise of YOLO and its complementary nature toward digital manufacturing and industrial defect detection[J]. Machines, 2023, 11(7): 677. doi: 10.3390/machines11070677 [44] WU Q, ZHANG B, XU CH G, et al. Dense oil tank detection and classification via YOLOX-TR network in large-scale SAR images[J]. Remote Sensing, 2022, 14(14): 3246. doi: 10.3390/rs14143246 [45] MA L, ZHAO L Y, WANG Z X, et al. Detection and counting of small target apples under complicated environments by using improved YOLOv7-tiny[J]. Agronomy, 2023, 13(5): 1419. doi: 10.3390/agronomy13051419 -

 下载:
下载:


计量
- 文章访问数: 316
- HTML全文浏览量: 190
- PDF下载量: 151
- 被引次数: 0
