


A saliency target area detection method of image sequence
-
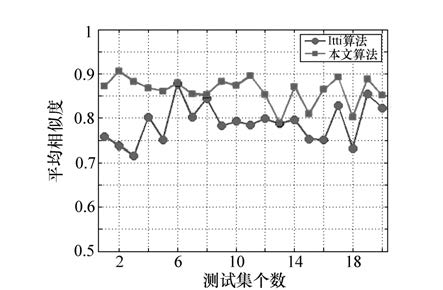
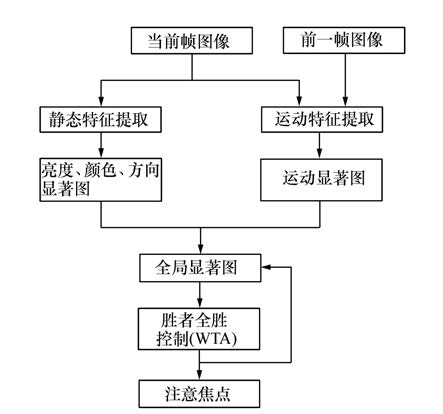
摘要: 针对传统视觉显著性模型在自顶向下的任务指导和动态信息处理方面的不足,设计并实现了融入运动特征的视觉显著性模型。利用该模型提取了图像的静态特征和动态特征,静态特征的提取在图像的亮度、颜色和方向通道进行,运动特征的提取采用基于多尺度差分的特征提取方法实现,然后各通道分别通过滤波、差分得到显著图,在生成全局显著图时,提出多通道参数估计方法,计算图像感兴趣区域与眼动感兴趣区域的相似度,从而可在图像上准确定位目标位置。针对20组视频图像序列(每组50帧)进行了实验,结果表明:本文算法提取注意焦点即目标区域的平均相似度为0.87,使用本文算法能够根据不同任务情境,选择各特征通道的权重参数,从而可有效提高目标搜索的效率。Abstract: For the lack of top-down task guidance and dynamic information processing of traditional visual saliency model, a visual saliency model fused with the motion features is designed and implemented. The static features and motion features are extracted based on the proposed model. The static features are extracted from the intensity, color and orientation channel of the current frame image. The motion features are extracted based on the multi-scales difference method. The saliency maps of four channels can be obtained by filtering and difference. Based on the proposed model a method of parameter estimation for multi channel is proposed to calculate the similarity between the region of interesting of current image and the region of interesting of eyes movement, then guide to generate the global saliency map, which can provide a calculation mechanism for accurate location on images. 20 groups of video image sequences(50 images per group) are selected for the experiment. Experimental results show that the average similarity of focus of attention is 0.87. The proposed method can more efficiently and accurately locate the region where the searched target may be present and can improve the efficiency of target searching.
-
Key words:
- visual saliency /
- top-down /
- target area detection /
- saliency map
-
表 1 多通道参数估计权值平均值的部分实验结果
Table 1. Part results of the avarage values of the multi-channel parameter estimation
 下载: 导出CSV
下载: 导出CSV
-
[1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] [16] -

 下载:
下载:


图(3) / 表(1)
计量
- 文章访问数: 2658
- HTML全文浏览量: 871
- PDF下载量: 736
- 被引次数: 0
